SEO
SEO - search engine optimization - оптимизация поиска контента нашего сайта поисковиками
SEO влияет на ранжирование наших страниц
Ранжирование - это сортировка результатов по более релевантным для нас значениям
Все страницы на нашем сайте собираются в связную паутину: с главной на продукты, с продуктов, на продукт, с продукта обратно на главную. По этой патуине передвигаются веб-краулеры.
Веб-краулеры передвигаются по страницам в рамках паутины движения по сайту и индексируют страницы.
Индексация - это процесс прохождения по этим страницам и сбор информации для ранжирования
Влияет на ранжирование в поиске:
- количество страниц
- индекс цитируемости
- популярность
- глубина отказов (если пользователь выходит со страницы через 20 секунд, то он с чем-то сталкивается)
- уникальность
- скорость
- контент
- удобство
- доступность
- скринридеры
- реагирование
- семантика
- роли
- ARIA-теги
- география
- uptime (время доступности сервиса)
- поддержка мобилок (почти половина пользователей сидит в интернете с телефона)
- навигация (не нужно индексировать мусорные страницы)
Мета
Теги
заголовка
Статичные
Первым делом, обязательно, для определения основного контенгента пользователей, стоит указать язык, на котором должен шейриться сайт
<html lang="ru">Обязательно дальше идёт кодировка. Меняется она редко и только под специфические языки.
<meta charset="UTF-8">vieport определяет поведение браузера при масштабировании на разных девайсах.
Например, админку на телефонах мы можем не давать приближать, а на маркетплейсах давать такую возможность, чтобы приближать картинки. Так же тут мы определяем дефолтный масштаб для сайта.
<meta name="viewport" content="width=device-width, initial-scale=1.0">Динамические
title - то, что отображается в строке браузера и выводится на главной поисковика. Тут должно быть максимум ключевых слов.
<title>Покупай и не грусти | Продаём книги</title>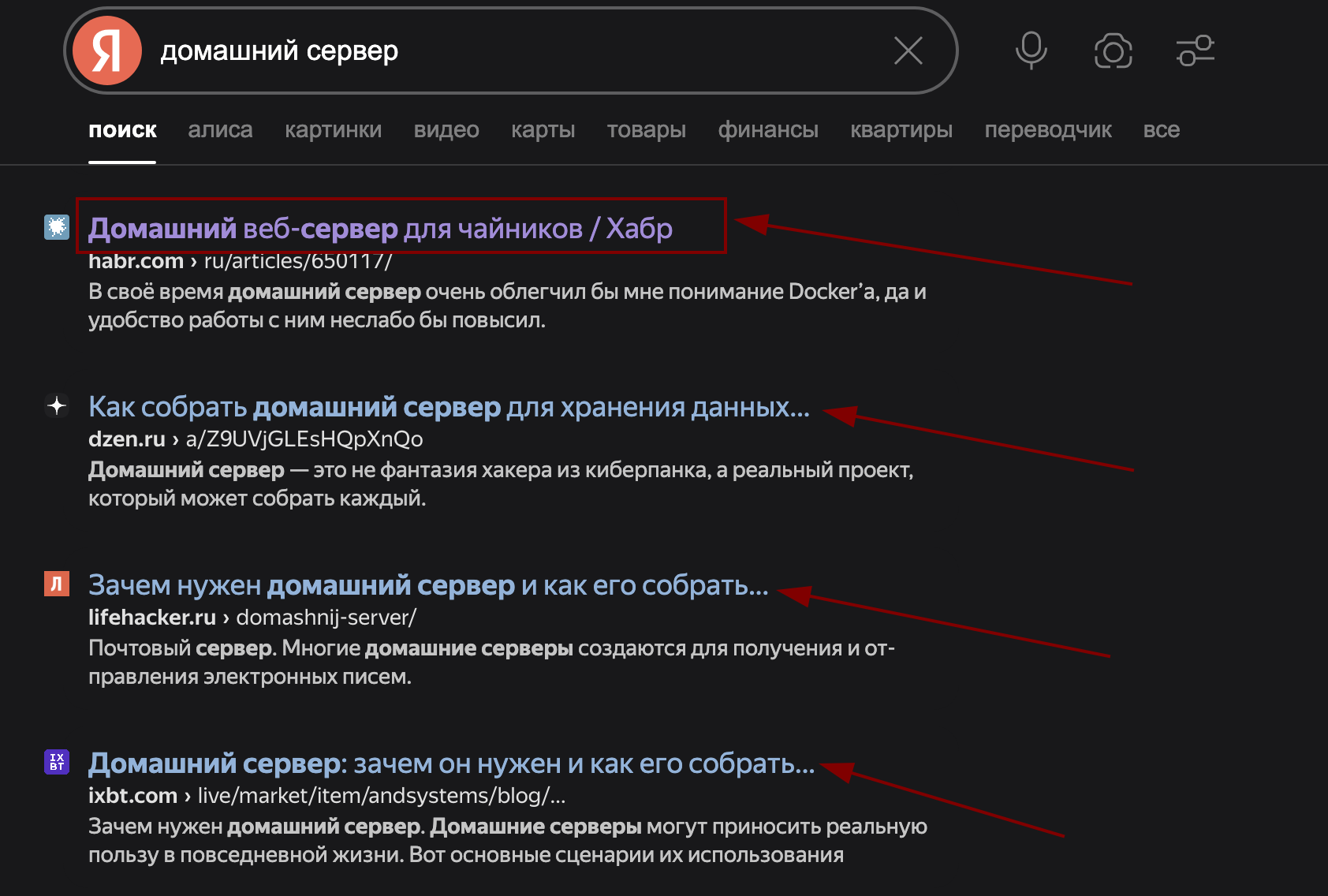
meta:description - это описание, которое так же должно содержать максимум ключевых слов
<meta name="description" content="Тут должно так же быть максимум ключевых слов...">meta:keywords - отдельная секция с ключевыми словами через запятую
<meta name="keywords" content="JS, JavaScript, TypeScript, SEO">Семантика
Очень важной частью является семантика самой страницы. Если нам важно ранжирование страницы, то верстать всё в рамках только div будет нельзя.
Нам для каждого своего элемента нужно обязательно будет:
- использовать свой семантический тег
- указывать роли
- обрабатывать действия
Тем более, правильные семантические теги дефолтно отрабатывают браузером правильно действия пользователя (клик по кнопке и так далее)
<body>
<header>
<nav>
<ul>
<li>s</li>
<li></li>
<li></li>
<li></li>
</ul>
</nav>
</header>
<aside>
<a href="http://ya.ru" target="_blank" rel="noopener noreferrer">Я внешняя ссылка</a>
<a href="/pupupu.html"></a>
</aside>
<section>
<h1>Единственный заголовок</h1>
</section>
<footer>
<div>
<p>тексты</p>
</div>
</footer>
</body>Open Graph
Open Graph - это протокол ссылок, который позволяет делиться дополнительной информацией в соцсетях. Они подтягивают изображения и мета-описание, когда делишься ссылкой.
og:type— определяет тип контента. Это помогает соцсетям понять, как правильно оформить блок при репосте.article(статья)website(общая страница сайта)videoи другие
og:url— канонический (основной) URL страницы. Помогает соцсетям и мессенджерам корректно агрегировать статистику, показывать нужный адрес при клике по карточкеog:title— заголовок, который будет показан в карточке при публикации ссылки. Обычно дублирует title или h1, но может быть короче и информативнейog:description— краткое описание страницы или статьи. Отображается в карточке под заголовком. Важно писать ёмко и привлекательно, чтобы увеличить кликабельностьog:image— ссылка на изображение, которое соцсеть или мессенджер подставит в превью карточки. Рекомендуется использовать картинки подходящего размера и без водяных знаков. Картинка влияет на привлекательность карточкиog:site_name— дополнительный тег, обозначающий имя сайта или проекта. Показывается в некоторых соцсетях, объясняет, откуда эта статья или страницаog:locale— язык страницы по формату ISO (например, ru_RU, en_US). Помогает определить локализацию контента. Используется не всегда, но улучшает предпросмотр для пользователей из нужного региона
<head>
<title>Пример страницы с OG</title>
<meta property="og:type" content="article">
<meta property="og:url" content="https://mysite.com/post/123">
<meta property="og:title" content="10 лучших практик фронтенд оптимизации">
<meta property="og:description" content="Ваш гид по эффективному ускорению сайтов на практике." />
<meta property="og:image" content="https://mysite.com/images/og-optimize.png">
<meta property="og:site_name" content="Frontend Blog">
<meta property="og:locale" content="ru_RU">
</head>Валидация HTML
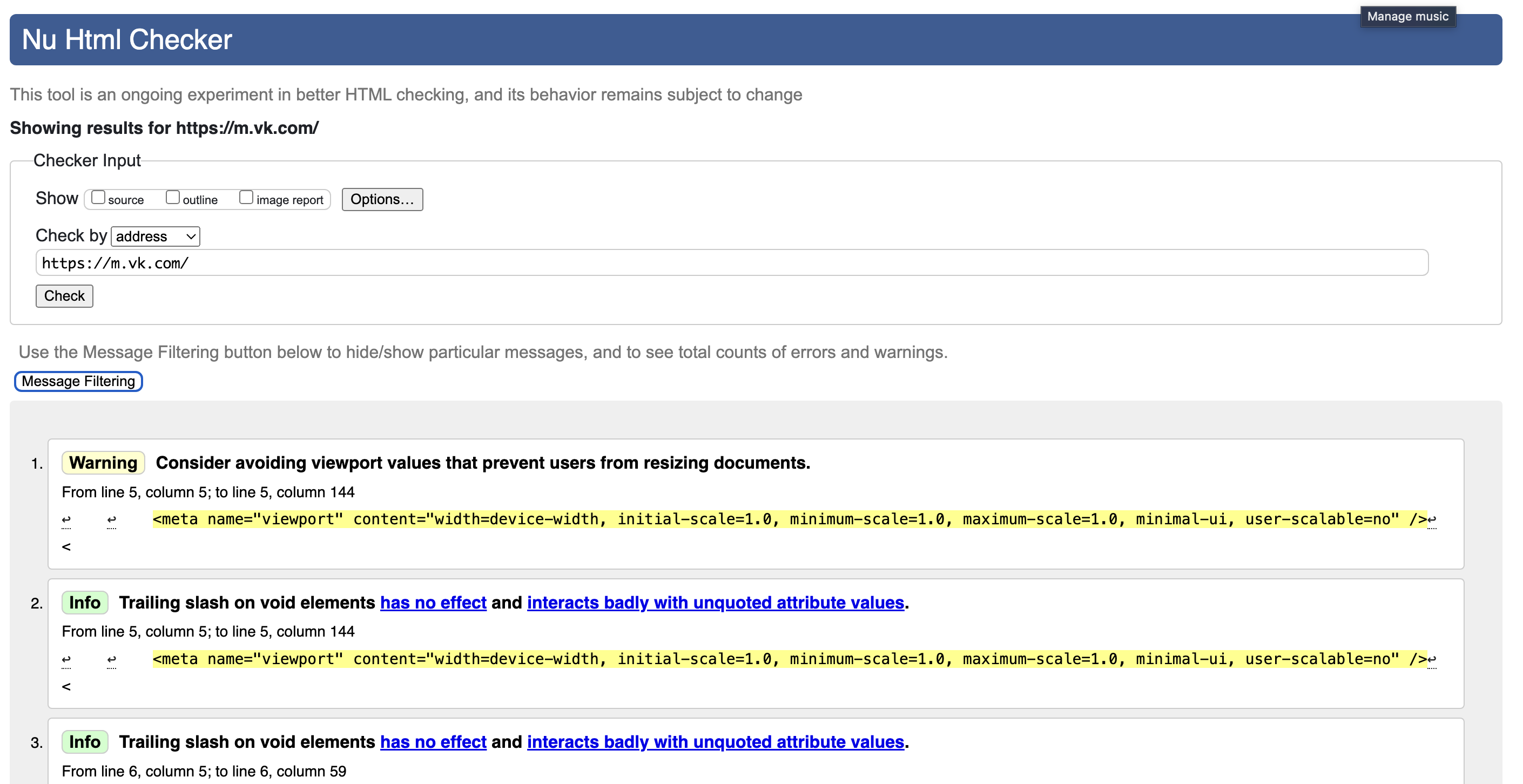
Валидировать разметку можно с помощью разных ресурсов, например validatorW3
Ссылки
ЧПУ
ЧПУ - человекопонятные ссылки - ссылки, содержание которых будет понятно обычному живому человеку
Например:
http :// cars.qq / auto / 123 / model / 4234- это пример плохой ссылки:- из контекста понятно только то, что она про машины, но дальше идут только цифры.
httpS :// cars.qq / auto / bmw / model / m5- это пример хорошей ссылки:- защищена ssl-сертификатом (только такие выводятся в поиск)
- в контексте указаны понятные наименования (выше конверсии)
Canonical links
Каноничные ссылки - это тег, который указывает на оригинальную страницу
Часто бывает такая ситуация, когда несколько ссылок ведут на одну страницу. Разные пользовательские пути приводят по разным ссылкам на одну и ту же страницу. Из-за этого у нас появляются дубликаты страниц. Чтобы поисковой робот не воспринимал страницы как дубликаты, нужно указывать каноническую ссылку, которая очищена от фильтров и других путей.
<!-- мы сейчас находимся на https://mysite.orig.com/products/books?filters=... -->
<link rel="canonical" href="https://mysite.orig.com/product/book/carl-marks/capital">Дубликаты тратят краулинговый бюджет!
Robots
Поисковые роботы - web crawlers, боты, пауки — это программы поисковых систем (Googlebot или YandexBot), которые автоматически переходят по страницам, анализируют их содержимое и добавляют в индекс.
Основная их задача — находить новые и обновлённые страницы для отображения в поисковой выдаче.
Бот:
- Переходит по ссылкам и картам сайта (sitemap.xml, внутренние и внешние ссылки)
- Загружает HTML и другие ресурсы
- Запрашивает вложенные файлы (CSS, JS, изображения)
- Проверяет, не запрещено ли ему что-либо robots.txt или мета-тегами
Теги
Задать значения для индексирования каждой страницы в отдельности мы можем через метатеги страницы со значениями:
index/noindex- включение / отключение индексацииfollow/nofollow- контролирует отслеживание изменения страницыall- включение всего отслеживания
<head>
<meta name="robots" content="noindex, nofollow" />
<meta name="googlebot" content="index, follow" />
<meta name="yandex" content="noindex, nofollow" />
</head>Robots.txt
robots.txt — это текстовый файл, размещённый в корне сайта https://mysite.com/robots.txt, который указывает поисковым ботам, что можно и нельзя сканировать на сайте.
С помощью него можно:
- Открыть или закрыть разделы сайта для индексации
- Контролировать нагрузку на сервер
- Защитить приватные или временные разделы от индексации
Файл состоит из директив:
User-agent:— для кого применяется правило (например, для всех, для конкретного бота)Disallow:— запрещённый путь (URL путь или папка)Allow:— явно разрешённый путь (чаще для конкретных файлов внутри запрещённой папки)- Дополнительно:
Sitemap:,Host:(Яндекс)
# правила для всех
User-agent: *
Disallow: /admin/
Disallow: /private/
Allow: /private/open-info.html
Disallow: /tmp/
# Разрешаем всё для Googlebot Images
User-agent: Googlebot-Image
Disallow:
# Указание карты сайта для всех
Sitemap: https://mysite.com/sitemap.xml
Файл максимум до 500 кб
Sitemap
Sitemap (карта сайта) — это файл, который содержит полный список важных страниц сайта.
Он помогает поисковикам быстрее и эффективнее находить и индексировать страницы, особенно если сайт большой, с глубокой структурой или с динамически генерируемыми страницами.
Sitemap:
- ускоряет обход сайта
- указывает поисковикам
- какие страницы есть
- когда они обновились
- какие из страниц приоритетнее для индексации
Формировать файл нужно из канонических ссылок
/sitemap.xml
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://mysite.com/</loc>
<lastmod>2025-10-01T12:00:00+03:00</lastmod>
<changefreq>daily</changefreq>
<priority>1.0</priority>
</url>
<url>
<loc>https://mysite.com/about</loc>
<lastmod>2025-09-28T09:30:00+03:00</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
<url>
<loc>https://mysite.com/blog/post-123</loc>
<lastmod>2025-10-03T15:45:00+03:00</lastmod>
<changefreq>weekly</changefreq>
<priority>0.9</priority>
</url>
<!-- Добавляйте столько <url>, сколько страниц хотите указывать -->
</urlset>Файл максимум до 50 мб, но в Sitemap можно указывать ссылки на другие карты сайта и реализовать сразу несколько сайтмапов, если ссылок крайне много
Этот файл нужно будет так же указать в файле robots.txt
/indexsitemap.xml
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="https://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>https://mysite.com/sitemap-main.xml</loc>
<lastmod>2025-10-01T08:30:00+03:00</lastmod>
</sitemap>
<sitemap>
<loc>https://mysite.com/sitemap-blog.xml</loc>
<lastmod>2025-09-29T12:00:00+03:00</lastmod>
</sitemap>
<sitemap>
<loc>https://mysite.com/sitemap-shop.xml</loc>
<lastmod>2025-10-02T17:45:00+03:00</lastmod>
</sitemap>
</sitemapindex>Мусорные страницы
Краулинговый бюджет - это количество ресурсов, которые может выделить краулер на выполнение индесирования
Бюджет тратится, когда у нас меняется количество страниц и при их обновлении.
Поэтому важно из индексирования выкидывать внутренние страницы и админку, чтобы не тратить бюджет.
Метрики
Web Vitals
Web Vitals - это ключевые показатели уязвимых мест приложения
LCP, FCP
LCP - largest contentful paint - время загрузки самого последнего чанка данных FCP - время загрузки первого контента
Нужно делить приложение на чанки и подгружать контент инкрементально, чтобы максимально снизить время первой загрузки контента, размер самого большого пакета и время загрузки последнего чанка данных.
FID
FID - first input delay - время до первой возможной интерации пользователя с сайтом
Первое взаимодействие пользователя с сайтом должно происходит как можно скорее, чтобы повышать скорость отклика приложения.
CLS
CLS - cumulative layout shift - общее смещение контента во время загрузки.
Пользователь начинает взаимодействовать со страницей, а потом у него часть контента съезжает. Либо скроллит до нужного абзаца, а изображение сверху подгрузилось и весь текст сместился. Нам в этом случае важно указывать заранее размеры элементов, загружать первоочередные чанки контента и реализовывать скелетоны.
Инструменты
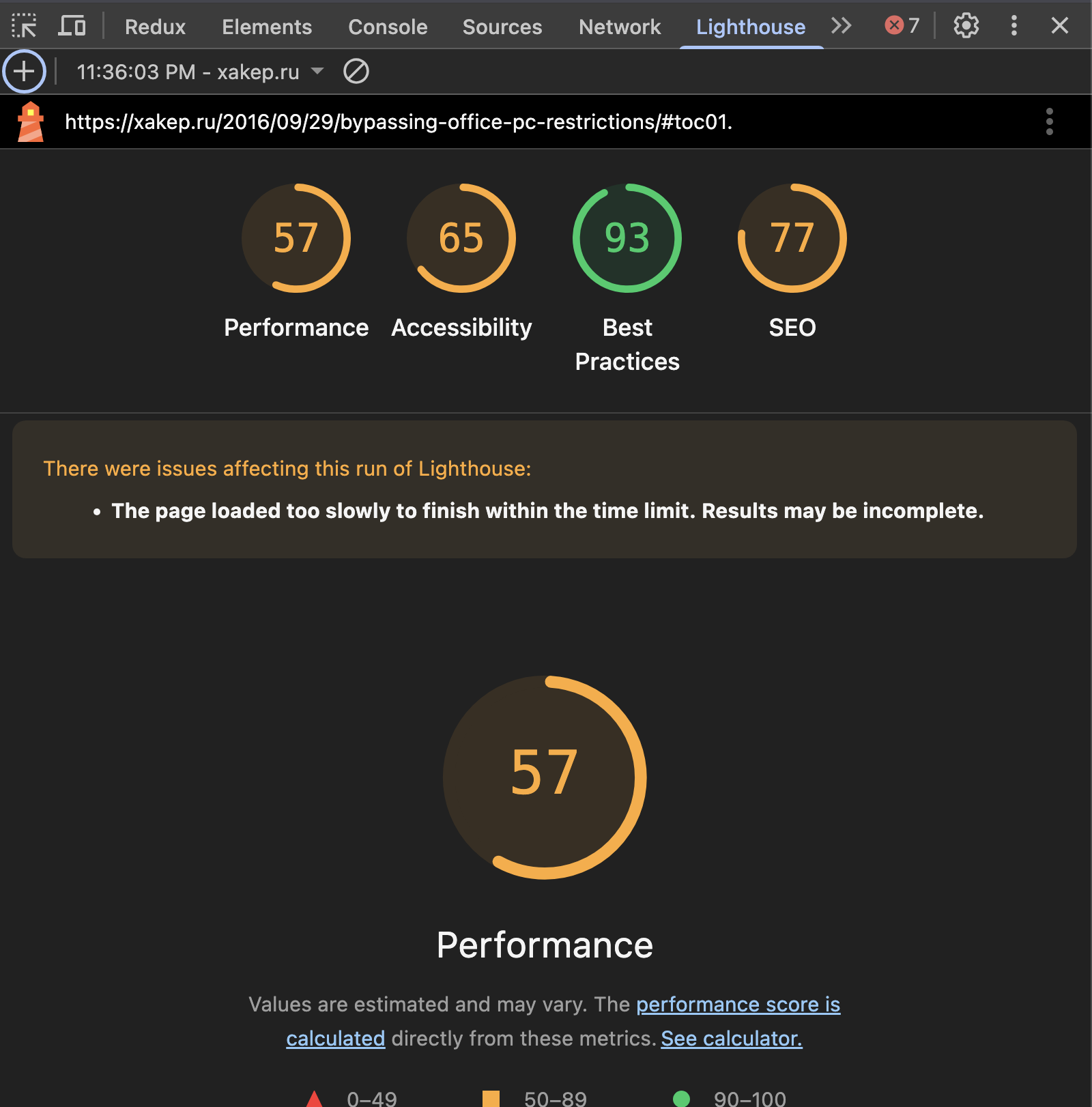
Page Speed Insights и Lighthouse - основные инструменты, которые покажут проседания по метрикам приложения. Первое работает только на задеплоенных ресурсах, а второе можно прогнать на локальном билде
Оптимизация - AMP
Современные сайты часто могут требовать дополнительную оптимизацию для работы с мобильными приложениями
AMP представляет собой фреймворк для использования в веб-приложениях и ускорения их работы на мобильных устройствах за счёт более оптимизированной разметки.
Такие сайты лучше работают на мобильных устройствах пользователя и лучше продвигаются
Редиректы
Настроить в конфиге NGINX:
- редиректы с
wwwна сайт безwww - редиректы с
httpнаhttps - со страниц без
/в конце на/в конце - со страниц с верхним регистром символов на страницы с нижним
- с
index.html|phpна главную страницу
Микроразметка
Микроразметка - это способ семантической разметки данных на сайте, который помогает лучше поисковым роботам определять тип информации, расположенной на странице
Мы можем реализовать таким образом:
- рейтинги
- списки
- хлебные крошки
- видео
- распродажи
- контакты
- отзывы
- и многие другие элементы
Например:
- Выйдет рейтинг к рецепту сразу на главной поисковика
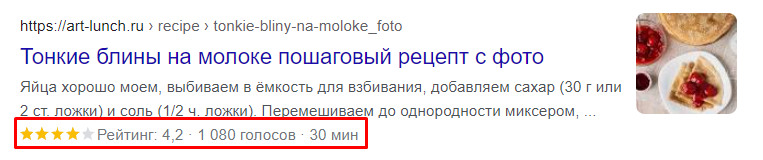
- Или выйдет список элементов афиши
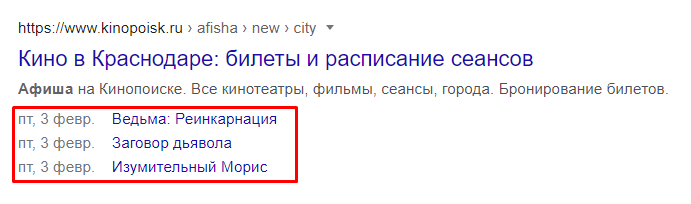
Есть несколько схем для реализации:
Microdata— добавляет атрибуты прямо в HTML-теги.RDFa— расширенная версия с похожими атрибутами.JSON-LD— содержит разметку в виде отдельного скрипта в формате JSON, рекомендованный Google вариант.
Пример JSON-LD:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "10 лучших практик фронтенд оптимизации",
"author": {
"@type": "Person",
"name": "Иван Иванов"
},
"datePublished": "2025-10-01",
"image": "https://mysite.com/images/article-image.jpg",
"publisher": {
"@type": "Organization",
"name": "Frontend Blog",
"logo": {
"@type": "ImageObject",
"url": "https://mysite.com/logo.png"
}
},
"description": "Гид по эффективному ускорению сайтов на практике."
}
</script>Пример Microdata (schema.org):
itemscope— объявляет, что этот блок описывает один объект (например, статью).itemtype— определяет тип объекта по словарю Schema.org (здесьArticle).itemprop— определяется свойство объекта, например:headline— заголовок статьи,author— автор (который сам является объектом Person с именем),datePublished— дата публикации,image— картинка (с дополнительным объектом ImageObject),description— краткое описание.
<div itemscope itemtype="https://schema.org/Article">
<h1 itemprop="headline">10 лучших практик фронтенд оптимизации</h1>
<p>Автор: <span itemprop="author" itemscope itemtype="https://schema.org/Person">
<span itemprop="name">Иван Иванов</span>
</span></p>
<p>Дата публикации: <time itemprop="datePublished" datetime="2025-10-01">1 октября 2025</time></p>
<div itemprop="image" itemscope itemtype="https://schema.org/ImageObject">
<img src="https://mysite.com/images/article-image.jpg" alt="Оптимизация сайта" />
<meta itemprop="url" content="https://mysite.com/images/article-image.jpg" />
</div>
<p itemprop="description">Гид по эффективному ускорению сайтов на практике.</p>
</div>Валидатор схем, через который можно их прогнать
SSR / SPA
SSR обеспечивает более надёжную и быструю индексацию страниц, нежели чем SPA, потому что:
- сервер сразу отдаёт полностью сформированный HTML с контентом, мета-тегами и уникальными URL, что упрощает и ускоряет индексацию
- боты получают читаемую страницу без необходимости выполнять JS
- подстраницы имеют отдельные URL с контентом, что удобно для SEO
- быстрее первые отрисовки страницы, что улучшает поведенческие факторы