Введение
Как выглядит деплой современного приложения:
- У нас есть готовый продукт, который мы билдим в приложение
- Далее нам нужно собрать из нашего приложения контейнер
- Сам контейнер будет попадать в наш registry, где будет сохраняться версия нашей сборки
- Далее уже большое количество разных образов оркестрируется с помощью kubernetes, либо с помощью немного устаревшего swarm

Swarm - это простое ручное решение для поднятия сразу нескольких контейнеров. Его проще поднять, а так же он является нативным решением. Основным его недостатком являются меньшие возможности относительно кубера и отсутсивие динамического масшатбирования проекта, если у нас будет не хватать мощностей.
Kubernetes - это более сложное решение для оркестрации большого количества контейнеров. У него есть множество готовых решений от различных провайдеров. Он чаще встречается на различных проектах, а так же он достаточно гибок в расширении и обновлении контейнеров. Он может предоставить нам инструментарий бесшовного релиза приложения без его остановки, что не может дать docker без ansible.

Настройка окружения
То, что находится на облаках и локально - это разные вещи. Локально находится только малая база.
-
Kubectl
-
CLI
-
VM driver - виртуальная машина для запуска
-
minikube - запускает одну ноду на VM и управляет ей
Minikube имеет огромное количество различных драйверов, через которые можно запустить VM
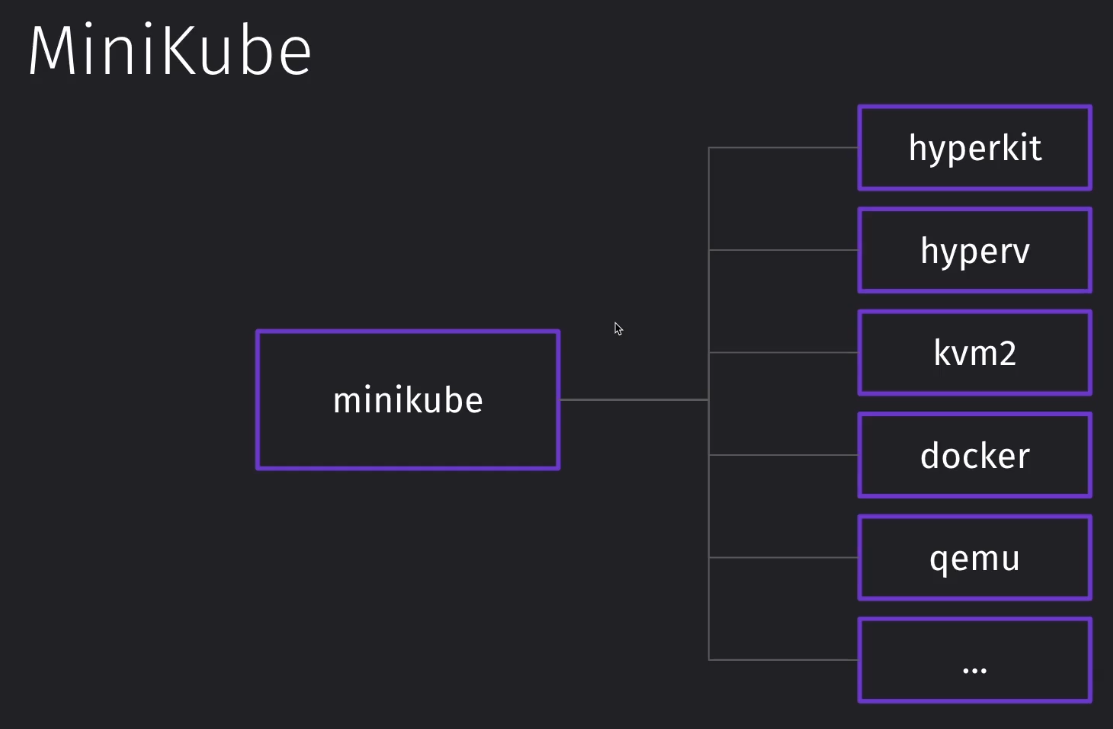
Установить всё дело можно и вручную по документации, но куда проще будет через homebrew
brew install kubectl minikube qemuДалее запускаем конфигурацию миникуба
minikube start --driver qemu
# либо
minikube start --driver dockerИ получаем список всех досутпных виртуалок
$ kubectl get all
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 83dЗнакомство с kubernetes
Разные окружения
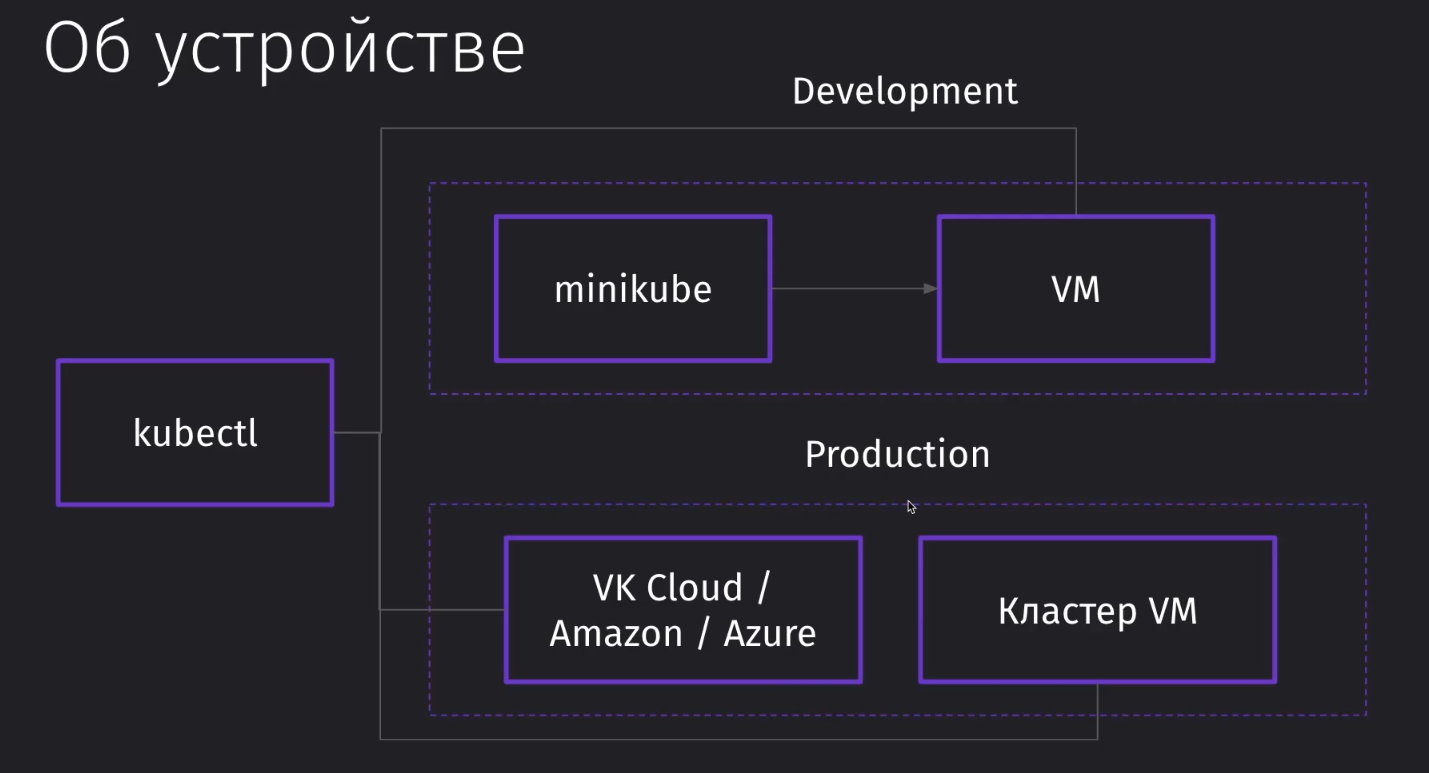
В рамках локальной разработки мы через kubectl обращаемся к виртуальной машине, которую мы настроили через minikube, и управляем ей.
В проде же у нас будет уже развёрнутый кластер виртуальных машин в стороннем облаке. Там уже будет находиться manage cluster, с которым мы сможем работать через kubectl. Можно и самому его настраивать, но без острой необходимости для работы большой системы - это малонеобходимо.
Компоненты
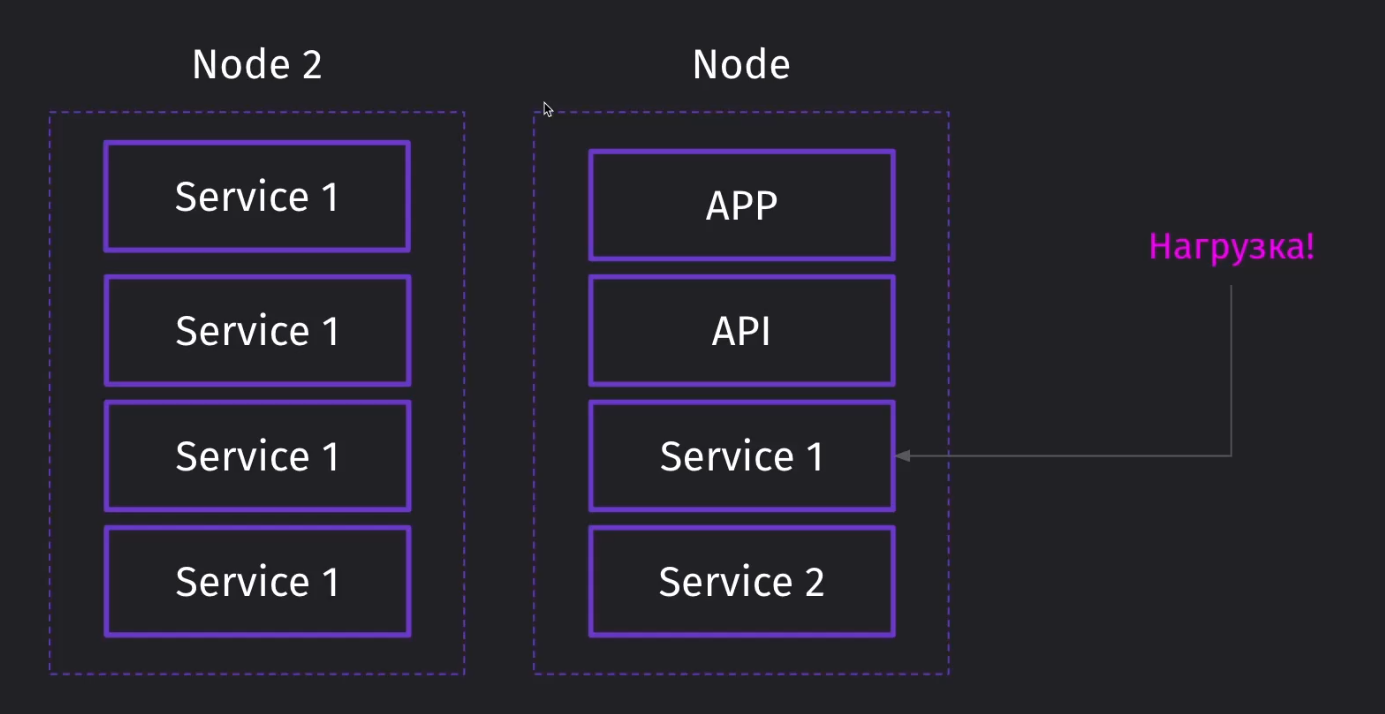
Представим, что у нас появилась достаточно высокая нагрузка на отдельный сервис в рамках отдельной ноды
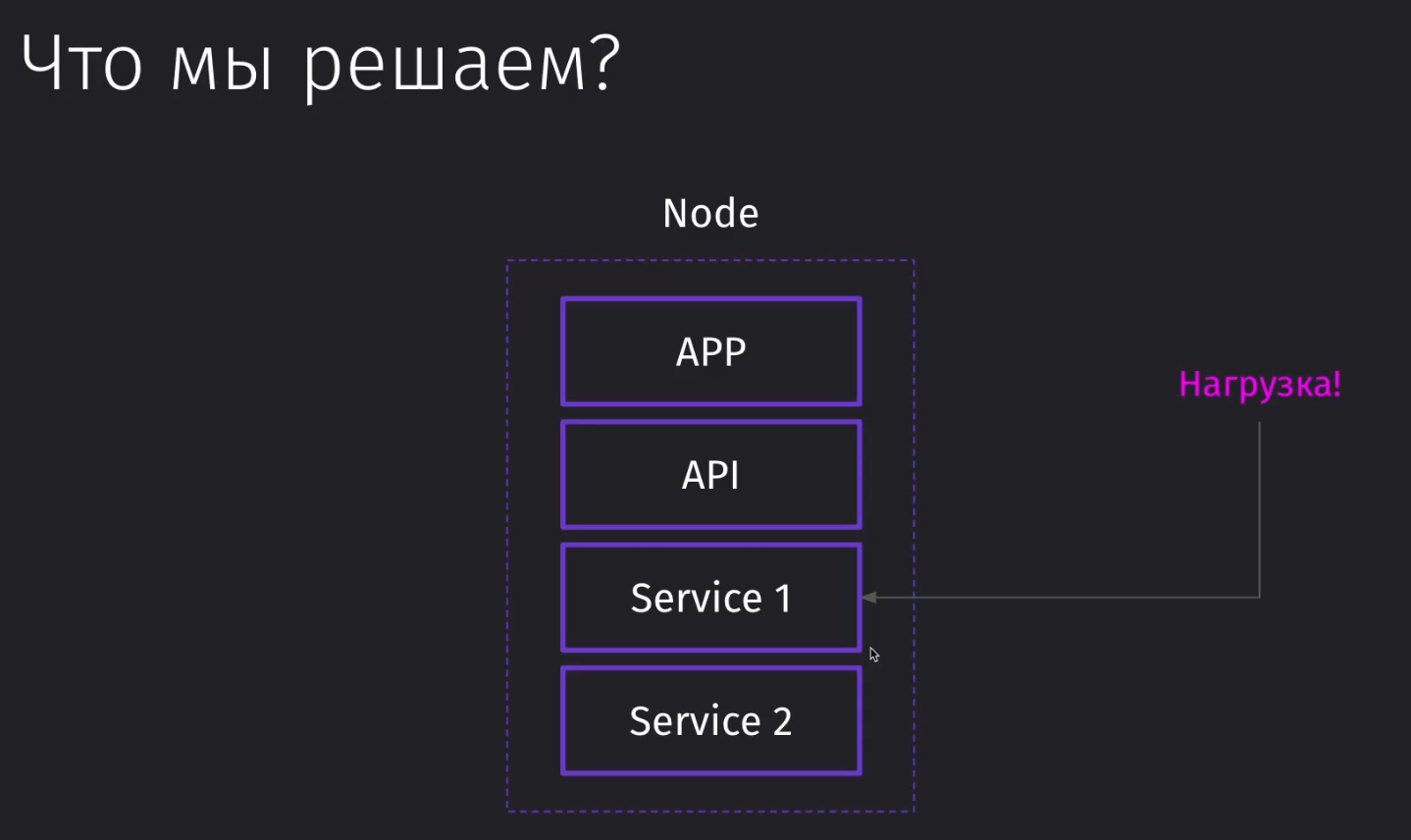
Если мы пойдём по классическому пути кластеризации, то мы можем поднять рядом в отдельной ноде инстанс наших микросервисов. Однако такой подход не будет эффективным, так как мы заняли много ресурсов вне нужного нам сервиса
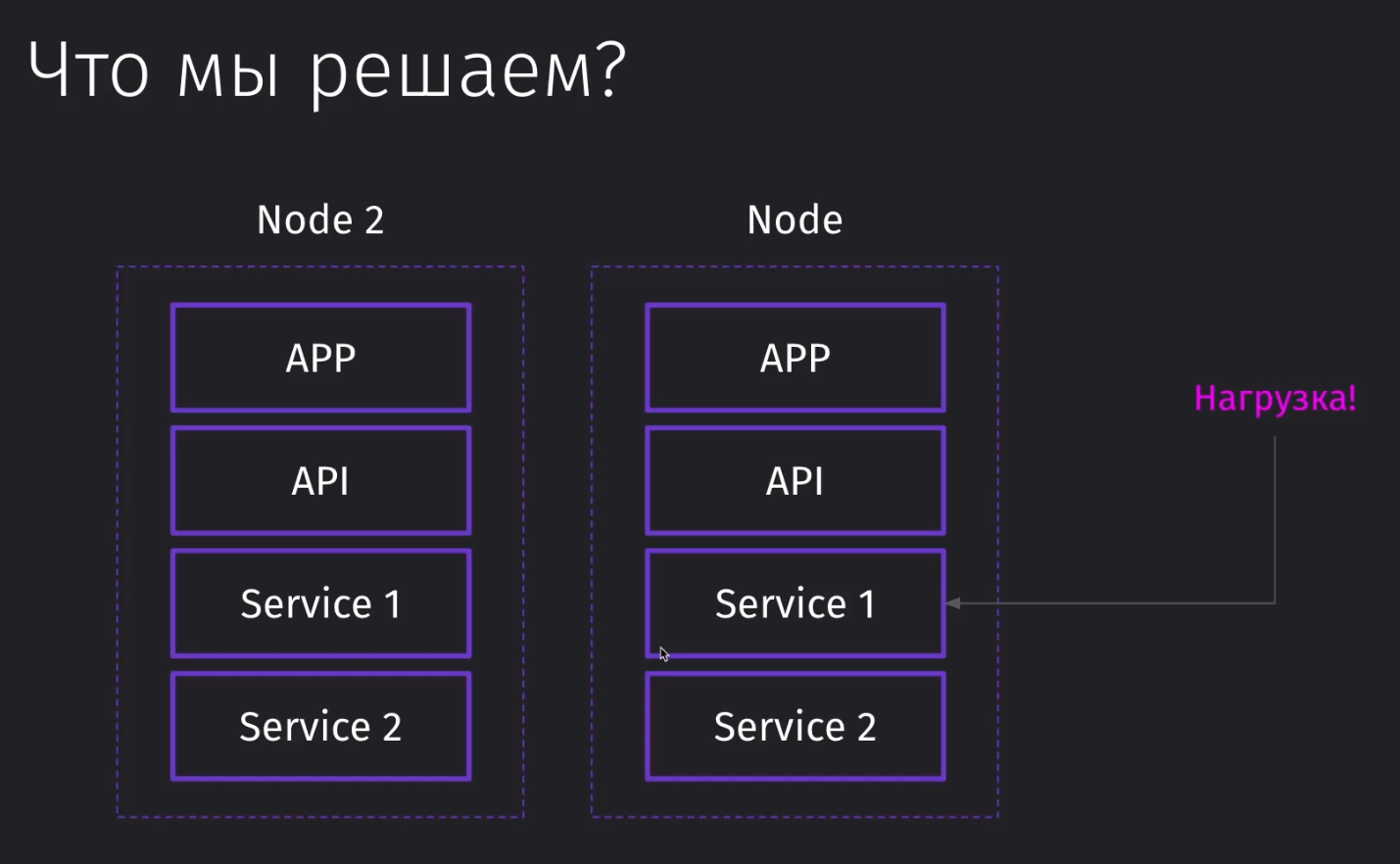
Через кубер у нас появится возможность поднять целую ноду определённого сервиса и легко отмасштабировать его, если появится большая лишняя нагрузка на сервис
Pod - это самая маленькая единица в kubernetes, которая представляет из себя элемент со своим IP и является абстракцией над определённым контейнером
Pod может из себя предствлять отдельный контейнер с NGinx, который будет отдавать статику сайта

Service - это элемент, который позволяет обеспечить постоянный доступ к контейнеру
Например, у контейнера всплывёт memory leak и при достижении порога потребляемой памяти, этот контейнер будет уничтожен
Каждому поду выделяется свой IP в рамках ноды и при пересоздании пода (упал/поднялся), ему переприсваивается другой IP. Отслеживанием обновления адресов и другой информации занимается сервис

Всего есть два типа сервисов, которые предоставляют доступ к внутренним объектам кластера извне:
-
NodePort
-
обращается
-
Ingress - обращается извне к поду по домену
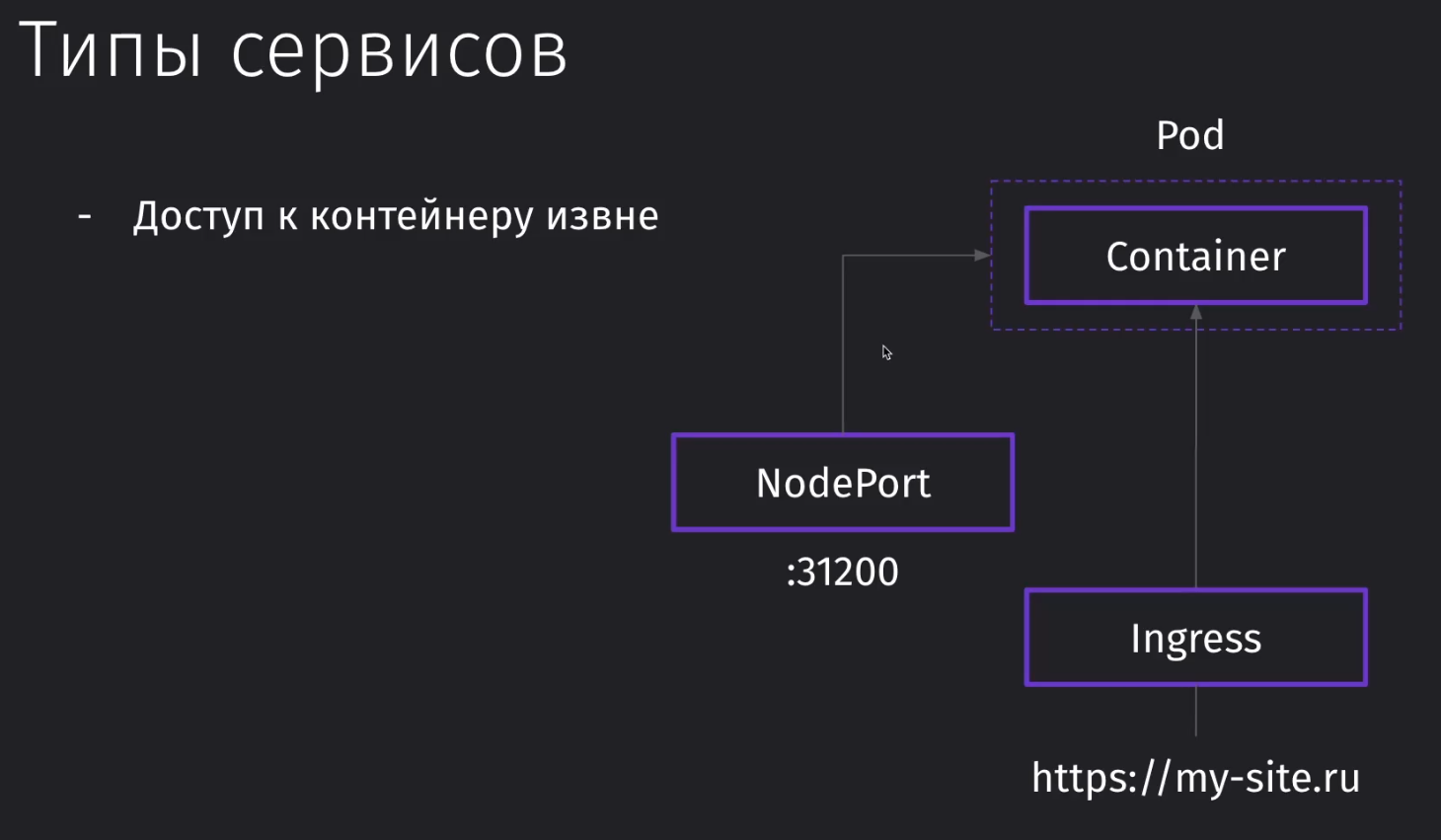
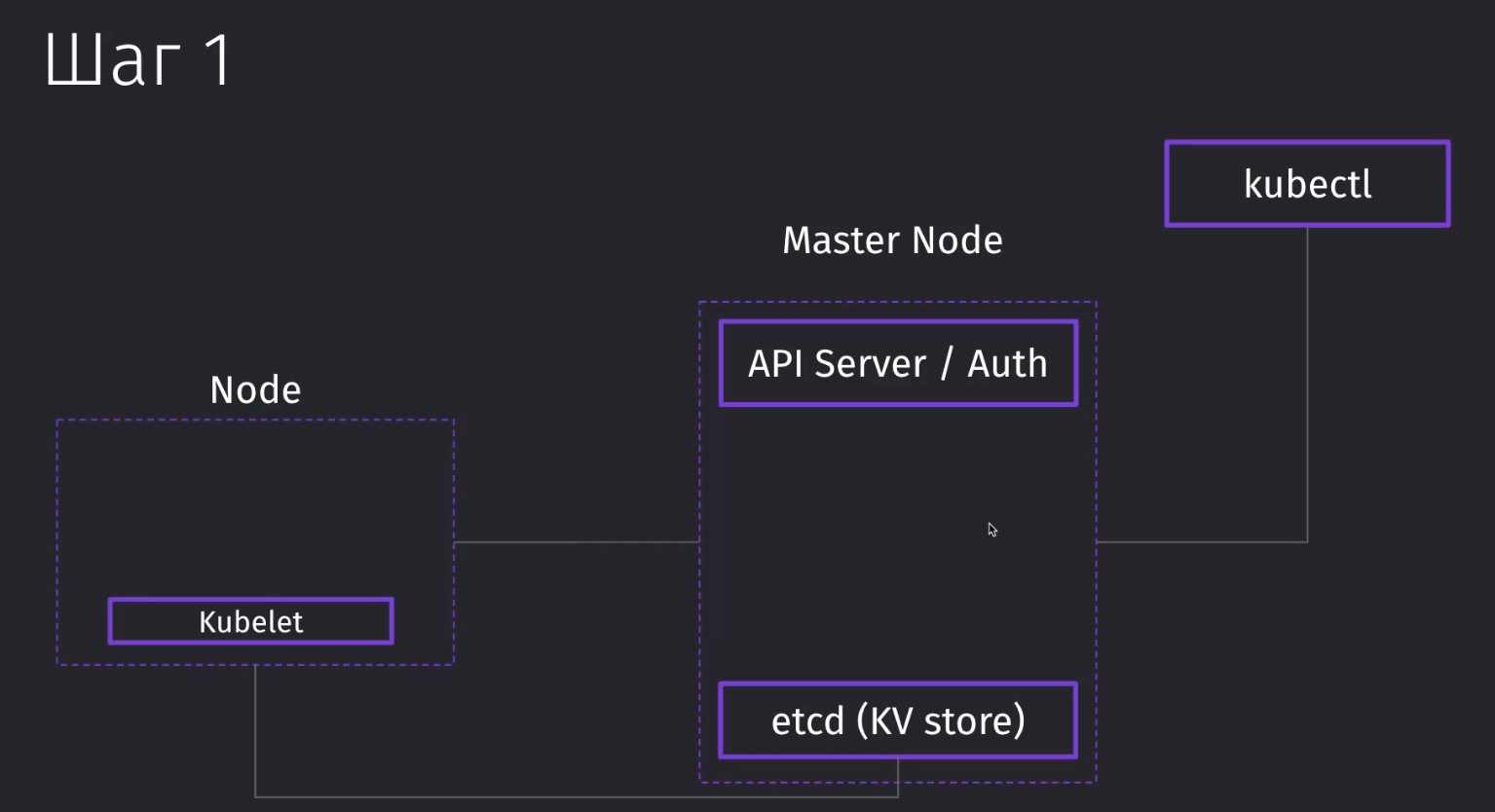
Устройство kubernetes
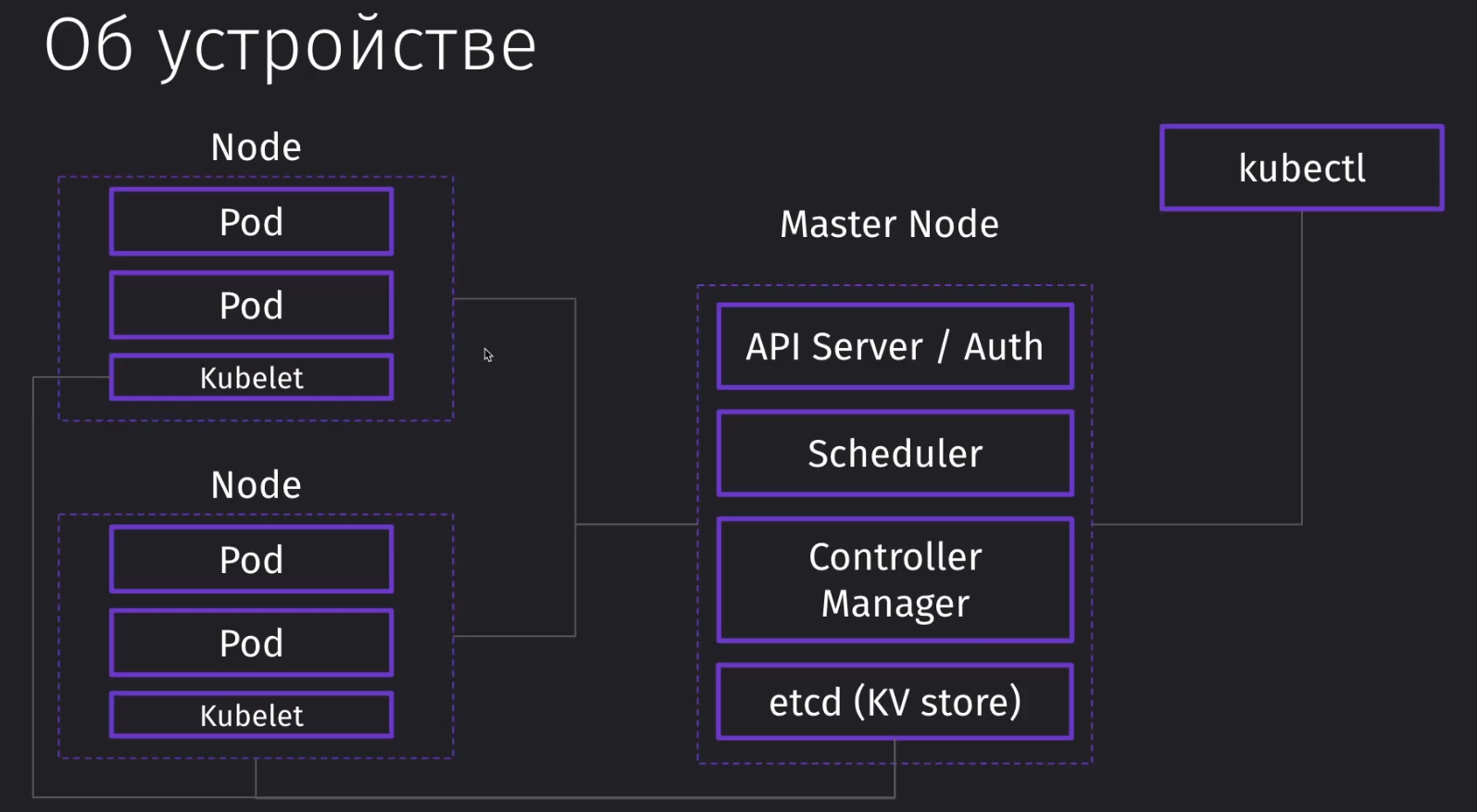
Node - это виртуальная машина или сервер, которая выполняет одну из двух ролей:
- Master Node - управляет работой подов
- Worker Node - хранит поды, которые непосредственно выполняются
В рамках minikube одна нода выполняет все функции
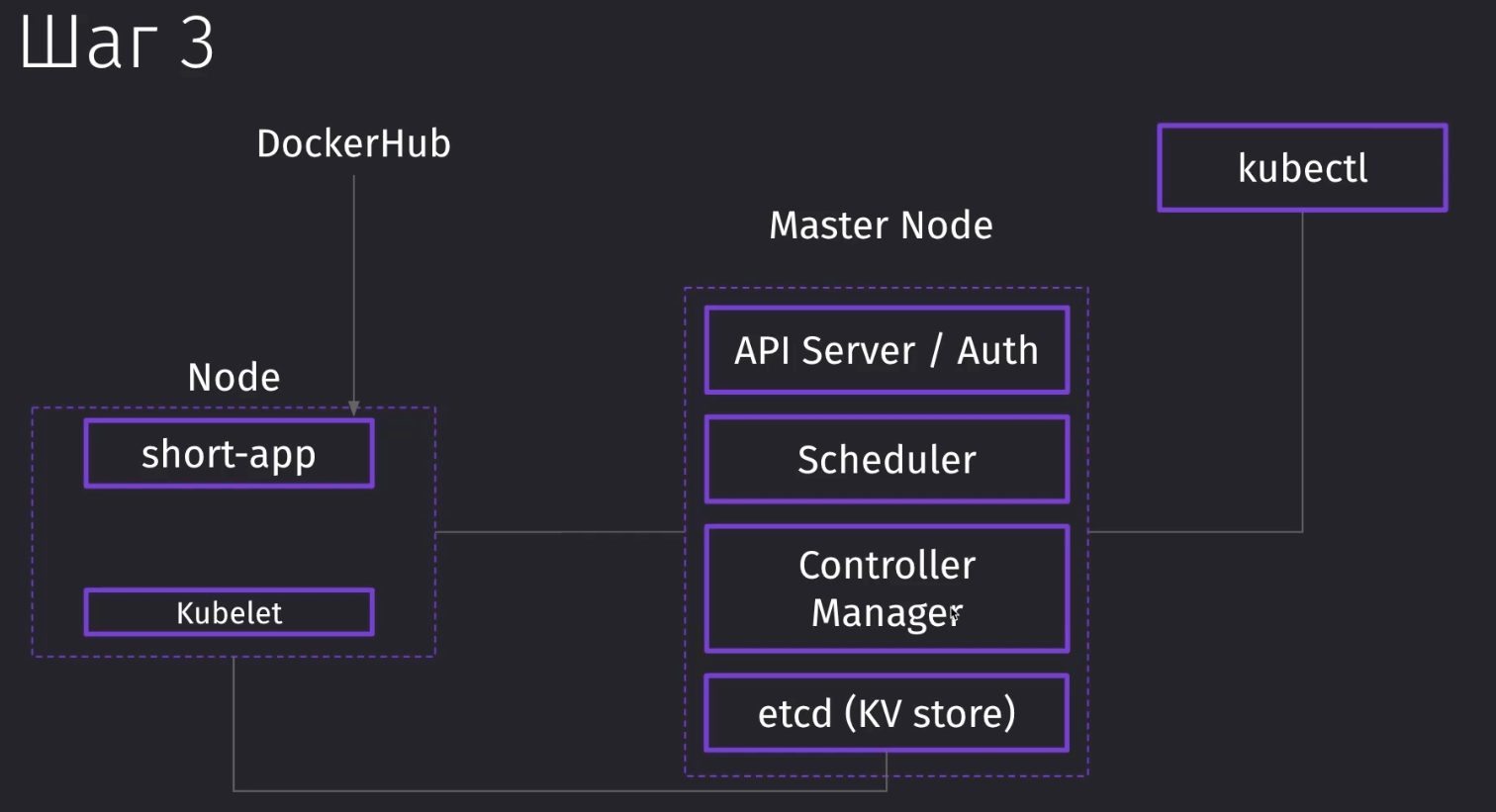
Kubectl - это одна из утилит, которая может обращаться к кубернетесу. Когда мы работаем с кластером через интерфейс, мы отправляем запросы в мастер ноду, которая управляет остальными подами. Через kubectl мы отправляем запросы на API Server, который находится в мастер ноде.
Если мы отправляем запрос на добавление ещё одного пода, наша операция попадает в Scheduler, который планирует размещение подов в нодах. Планировщик отправляет задание ноде поднять нужный нам под.
Само задание, которое мы получили из мастер ноды от планировщика, выполняет kubelet. Это процесс, который непосредственно вызывает поднятие пода с нужным контейнером.
Сам планировщик имеет информацию о нагрузке каждой ноды и отправляет задание в наименее нагруженную.
Кроме планировщика нам может потребоваться контроллер, который будет управлять жизненным циклом кластера. Если какой-то под упал, то его нужно будет поднять и максимально сохранять заданную конфигурацию кубера, которая была задана человеком. В этом случае нам может понадобиться Controller Manager, который контролирует как поды, так и целые ноды, умея перераспределять их, если какие-то из серверов вышли из строя.
Всю информацию каждый элемент не хранит в себе, а берёт и записывает в Key-Value Storage, в котором находится информация о нодах, подах и их метаданных.
Так же у нас имеются и другие элементы системы, как Volumes, Configs, Secrets и так далее.
Мастер нод так же может быть несколько.
Разные подходы
При работе с Kubectl у нас есть несколько подходов к работе с ним
Императивный подход
Мы явно указываем то, что мы хотим сделать
Тут мы напрямую взаимодействуем с кластером и просим поднять сервер nginx, который никогда не будет перезапускаться
kubectl run nginx --image=nginx --restart=Never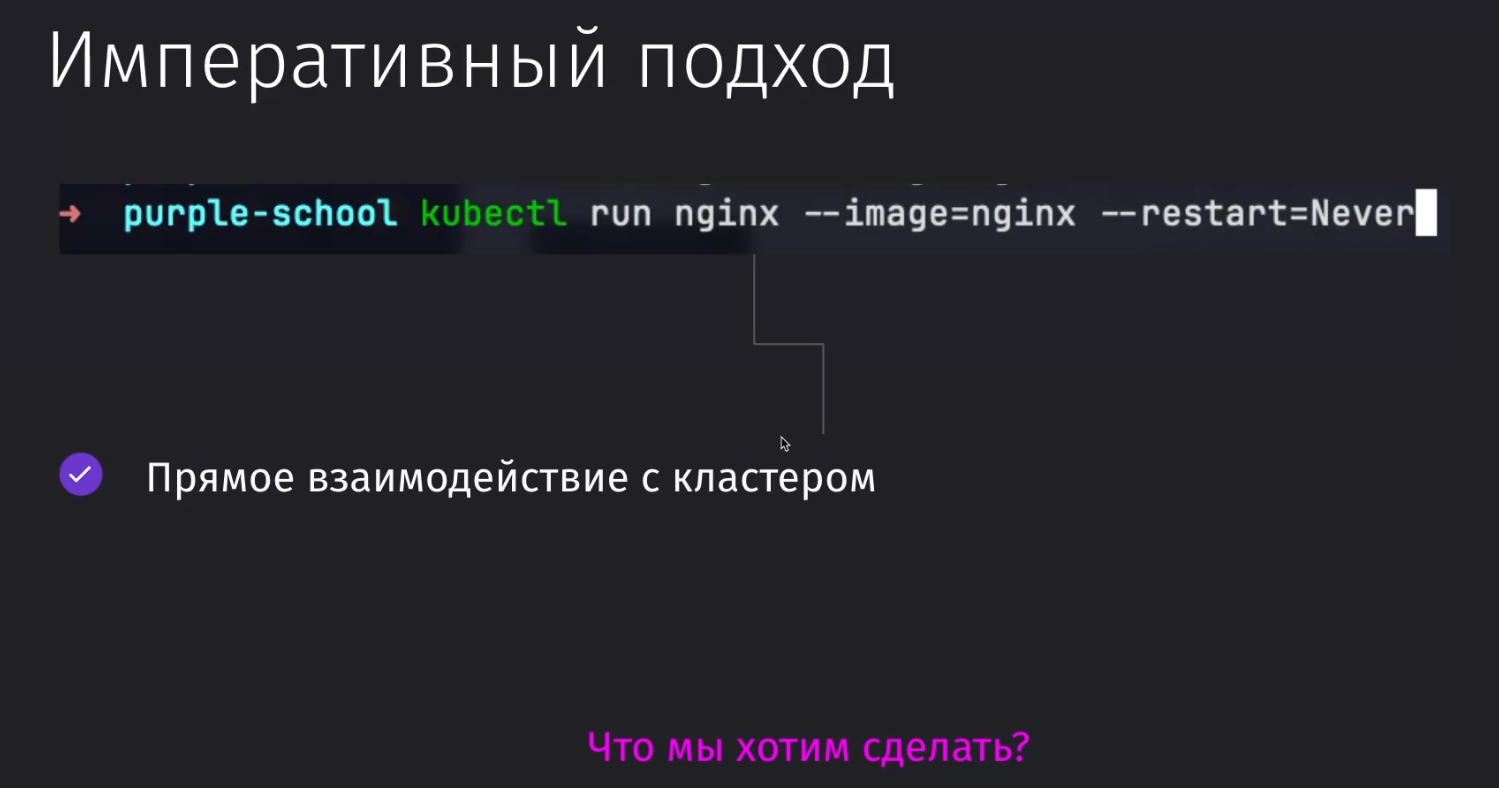
Декларативный подход
Мы указываем конечный результат, которого хотим добиться.
В таком случае мы идём от конфига или идеального вида системы, которого хотим добиться

Когда применять?
Императивный для коротких операций и тестирования, а декларативный нужно применять для поддержки IaC, историчности и для работы с командой разработчиков

Конфигурации
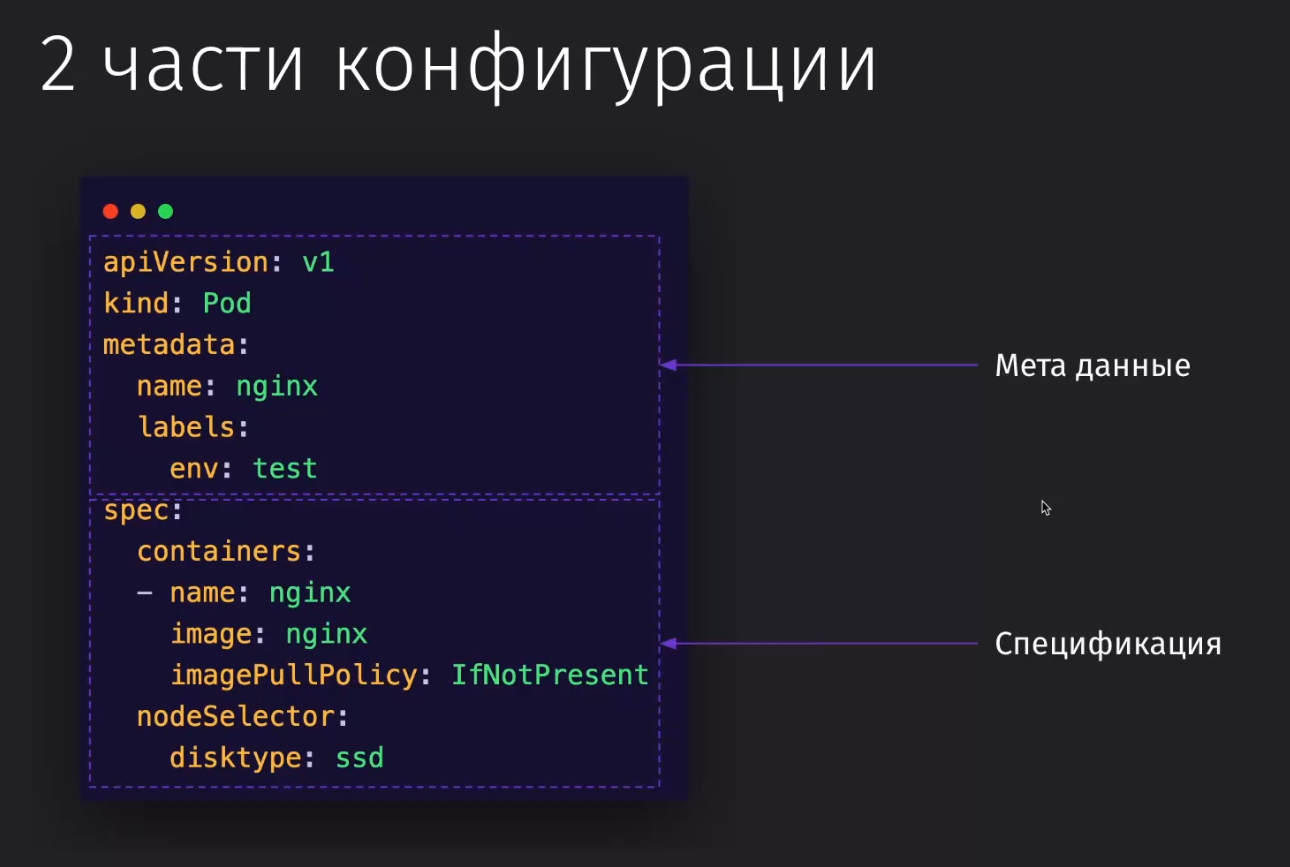
Конфигурация Kubernetes делится на две части: метаданные и спецификация
- Метаданные
- версия
kind- это тип контейнера, котрый мы описываем (Pod, Service, Node)metadata- метаданные по описываемому сервису, которые нужны для связи объектов друг с другом
- Спецификация
Её ключи зависят от типа kind, который мы указали, так как для каждого типа контейнера будут свои поля
- обозначение
containers- список объектов с описанием контейнеровname/image/imagePullPolicy- конфигурации контейнера (имя, изображение, политика пуллинга изображеия)nodeSelector- конфигурации сервера (ноды), на которых нужно запускать контейнерdisktype- тип дисков, на которых должна запуститься нода
apiVersion принимает два параметра: v1 и apps/v1. Второй нужен для того, чтобы управлять другими объектами.

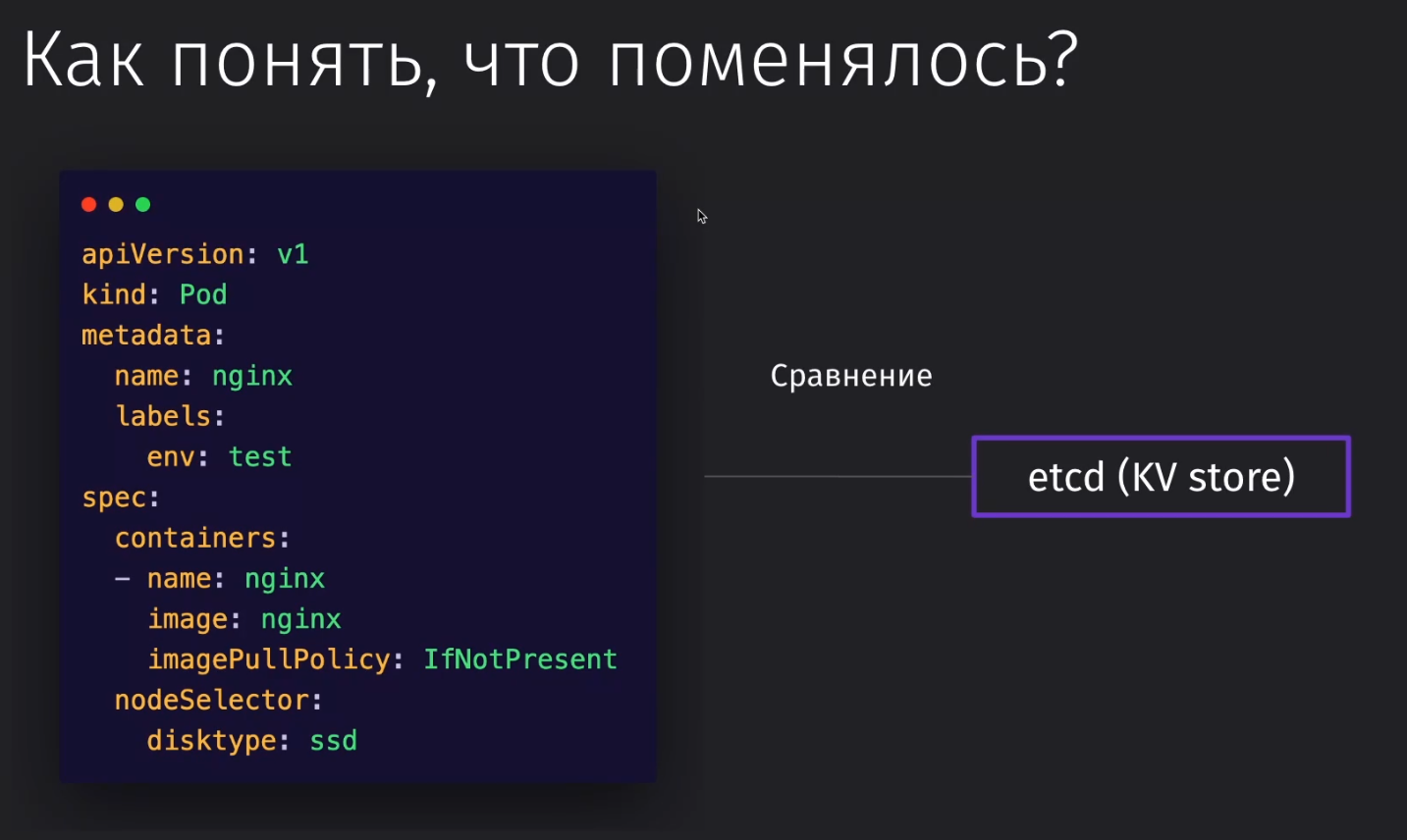
Kubernetes парсит конфиг и все настройки, которые мы описали, складывает в etcd хранилище, которое используется другими компонентами системы для построения всех нод и подов и сведение их с описанной структурой из конфигурации
Первый pod
О приложении
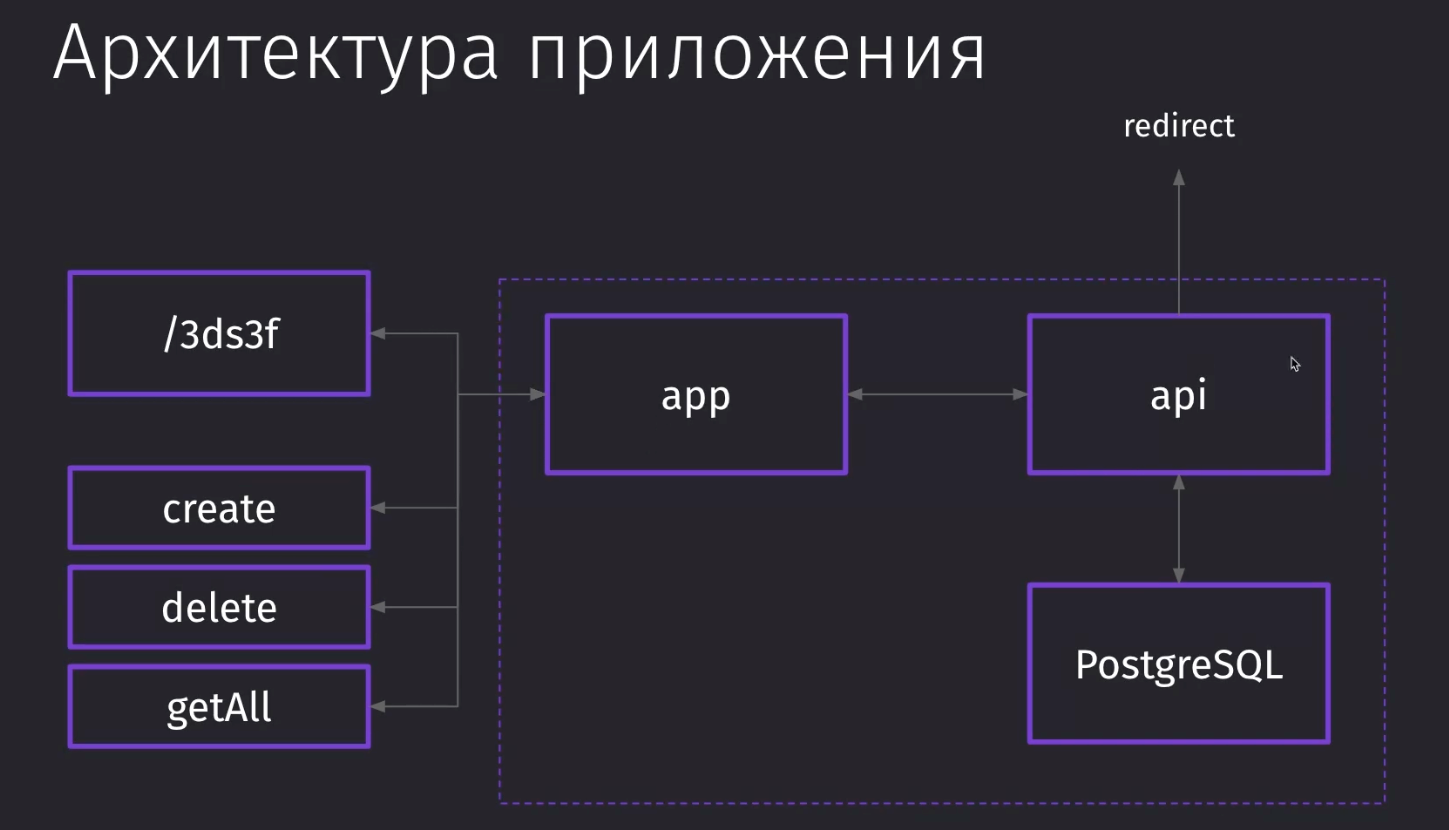
Приложение для сокращения ссылок:
- app сокращает ссылки
- api общается с app
- postgresql занимается хранением данных о ссылках
- ресты
create/delete/getAll- создают, удаляют и получают все ссылки /<rest>- тут уже происходит редирект
Первый POD
Главное отличие pod от контейнера заключается в том, что это может быть абстракция над несколькими контейнерами. То есть мы можем запустить контейнер с PGSQL и контейнер, который будет его бэкапить.

Далее укажем такую конфигурацию, в которой будет:
- находиться наш собственный image с docker-образом приложения
- в
portsукажемcontainerPort, который нам нужно прокинуть наружу, чтобы иметь доступ для получения статики сайта от NGINX - обязательно указываем
resources, в котором у нас стоят лимиты, при достижении которых, наш сервис будет перезапущен
pod.yml
---
apiVersion: v1
kind: Pod
metadata:
name: short-app
labels:
components: frontend
spec:
containers:
- name: short-app
image: antonlarichev/short-app
ports:
- containerPort: 80 # прокидываем наружу порт контейнера с NGINX
# обязательно указываем максимальные ресурсы, которые может кушать контейнер
resources:
limits:
memory: "128mi" # mi - mb
cpu: "500m" # m - miliprocessors - величина относительная к процессору, но указывает количество доступной нагрузкиСервис
Сервис позволяет держать с контейнером постоянную связь. Без сервиса нам придётся получать связь каждый раз по IP, который может в любой момент поменяться после редеплоя, если сервис уйдёт в memory leak или упадёт по любой другой причине.
Сервисы бывают 4ёх типов:
-
Ingress
-
позволяет
-
NodePort - позволяет прокинуть порт изнутри контейнера наружу
-
ClusterIP - позволяет общаться сервисам между друг другом (front - back) внутри кластера
-
LoadBalancer - балансирует нагрузку, предоставляя доступ к 1 из сервисов извне, который менее всего загружен

Пользователь обращается к IP-адресу кластера, где запрос уходит на прокси, который ретранслирует через себя все запросы от кластера до определённого сервиса. Потом на сервис, который выводит порт из POD в мир.
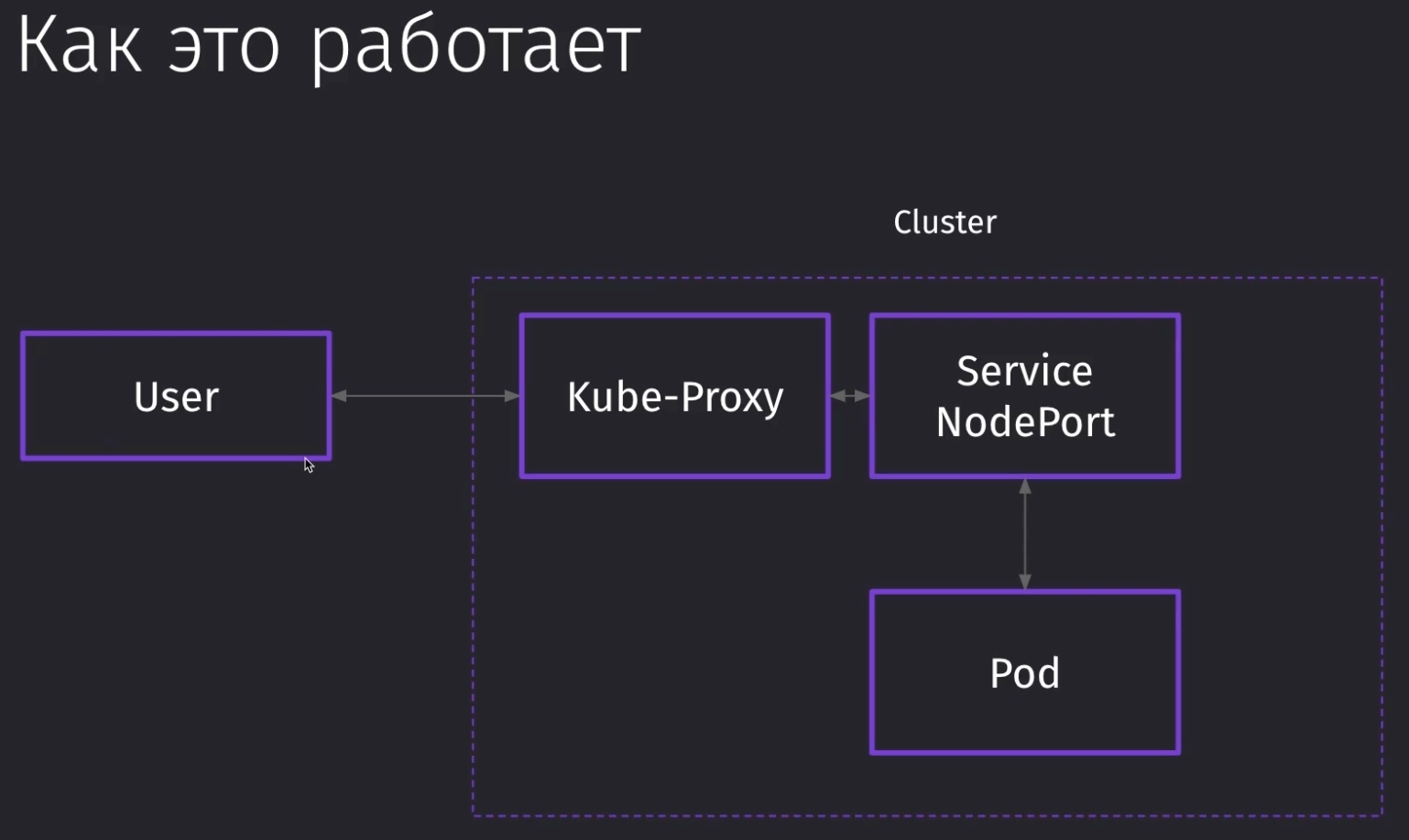
Kube-Proxy требует, чтобы в конфиге было понятно, откуда и куда какой порт проксировать. Поэтому нам нужно будет указать в спеках порты прохода запросов.
nodePortговорит, что при обращении к кластеру по данному порту, мы должны прокинуть запрос в определённый сервис (в котором мы указали этот порт)targetPortговорит нам на какой порт пода мы должны стучаться, когда уже попали в сервисport- это внутренний порт для кластера, по которому другие поды смогут достучаться до нашего пода
Для доступа извне нам нужна связка nodePort и targetPort. В нашем случае, targetPort будет равен containerPort из конфига пода, так как через targetPort нам нужно достучаться до приложения извне кластера
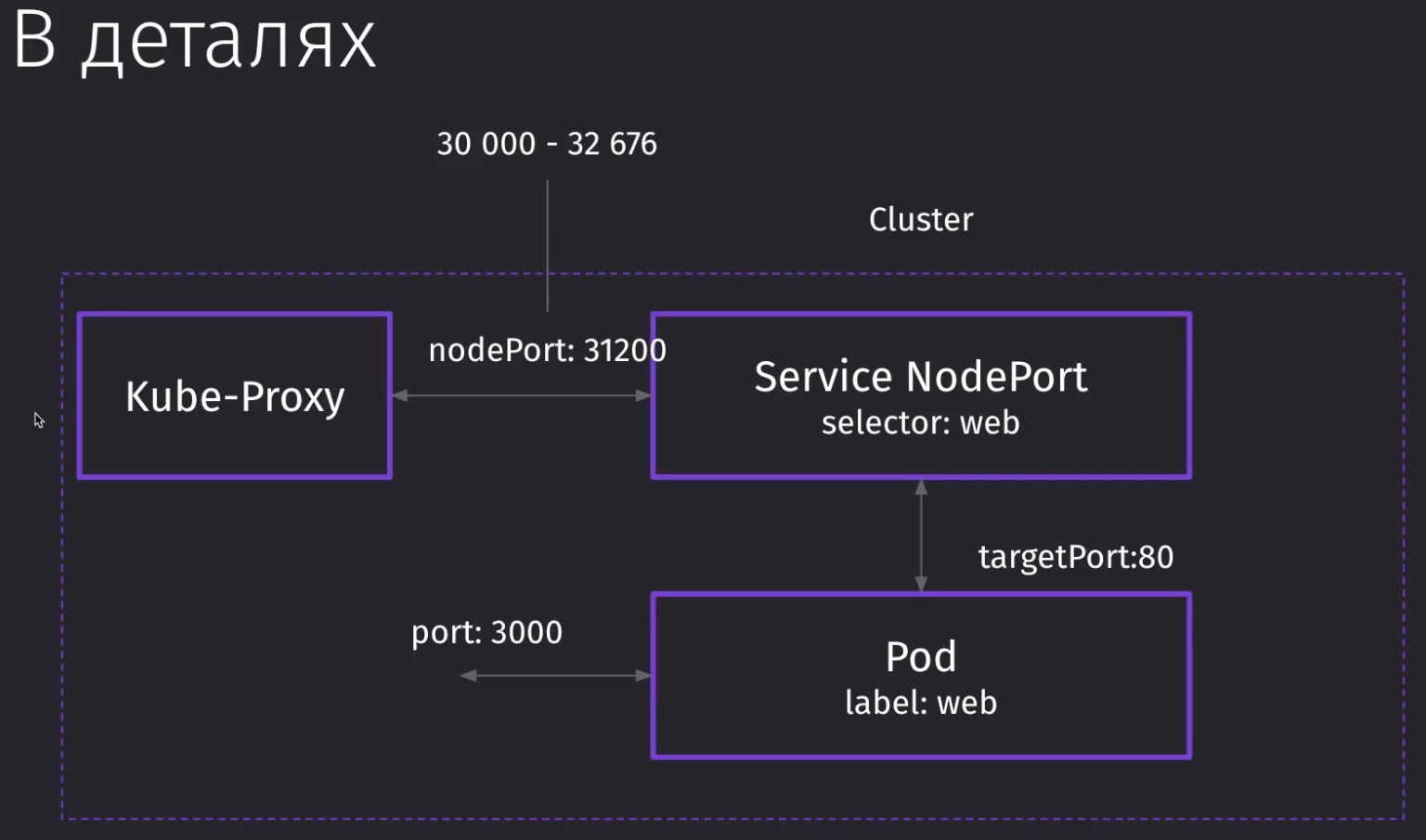
Дальше нам останется только привязать сервис к определённому поду через селектор. В качестве селектора будет выступать заданный ранее лейбл в поде
node-port.yml
---
apiVersion: v1
kind: Service
metadata:
name: short-app-port
spec:
type: NodePort
# порты для доступа к контейнеру извне кластера
ports:
- port: 3000
targetPort: 80
nodePort: 31200
# селектор для связи пода и сервиса
selectors:
components: frontendЭтот сервис node-port.yml позволит нам подключиться извне (то есть получить ответ вне kubernetes) по порту 31200 к сервисам, для которых он открыл доступ (к фронту).
Подключение к контейнеру
Через утилиту kubectl мы можем выполнять все операции по работе с кластером.
Применение конфига
Через apply мы можем применить определённый конфиг к нашему кластеру для выполнения.
# запускаем все файлы в папке
kubectl apply -f .
# либо можно запустить отдельный файл
kubectl apply -f pod.ymlИнспект конфига
Через get мы можем проинспектировать определённый элемент нашей системы.
all позволяет получить все возможные образы, которые были запущены ранее в определённом кластере
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/short-app 0/1 ErrImagePull 0 13s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 5m25s
service/short-app-port NodePort 10.110.44.54 <none> 3000:31200/TCP 4sТак же ничто нам не мешает вывести только поды
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
short-app 1/1 Running 0 3m43sНу и так же отдельно можно взглянуть на запущенные сервисы
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 11m
short-app-port NodePort 10.110.44.54 <none> 3000:31200/TCP 6m8sКоннект к контейнеру
Чтобы отправить запрос в кластер, нам нужно будет получить ip кластера, который мы создали через minikube
$ minikube ip
192.168.58.2Теперь можно по http://192.168.58.2:31200 получить доступ к фронту, который был поднят из кубера
Как работает запуск
kubectl отправил запрос в Master ноду в API Service и передал в него конфиг
Дальше планировщик ищет ноду, где он сможет запустить наш конфиг short-app. У нас пока одна нода.
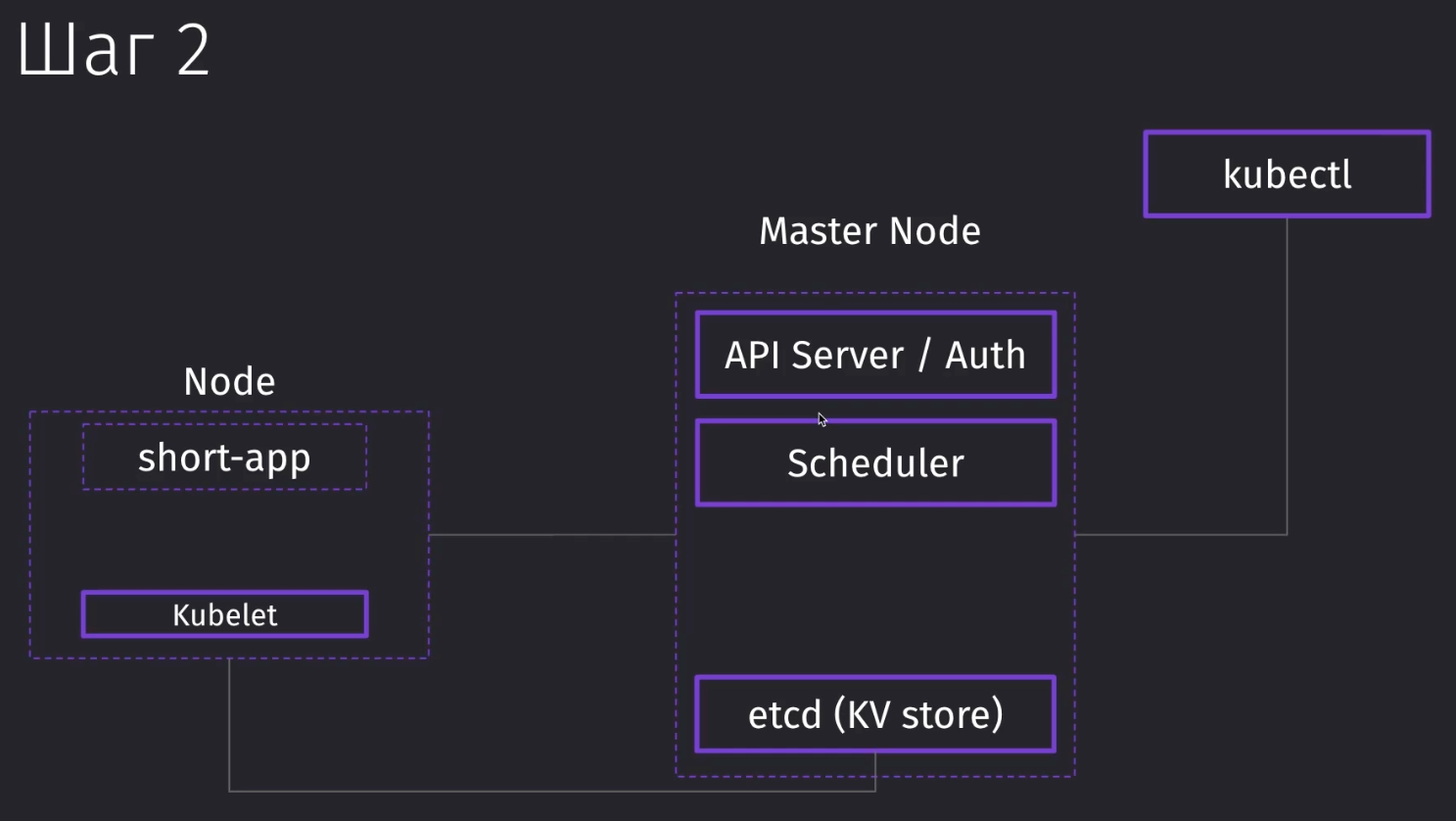
Дальше уже Controller Manager зафиксировал тот факт, что у нас должен быть один инстанс short-app.
Если наше приложение упадёт, то CM попросит запланировать Scheduler снова поднять контейнер в ноде.
На этом же шаге kubelet (администрирующий нашу ноду) стягивает image из dockerhub и поднимает POD
Со стороны Pod у нас всего несколько этапов:
-
Scheduled
-
запланирован
-
Pull - стягивает image, если его нет локально, чтобы запустить
-
Create - создаётся Pod
-
Start - запускается Pod с контейнером
Чтобы получить полностью всю информацию о запуске пода, мы можем воспользоваться kubectl describe, где есть вся информация по подах
$ kubectl describe pods short-app
Name: short-app
Namespace: default
Priority: 0
Service Account: default
Node: minikube/192.168.58.2
Start Time: Sun, 22 Jun 2025 16:30:10 +0300
Labels: components=frontend
Annotations: <none>
Status: Running
IP: 10.244.0.3
IPs:
IP: 10.244.0.3
Containers:
short-app:
Container ID: docker://465ab518889b248c72f6aaad19df0bef319f53a7edc3d9ff4fd105e2e9b1d378
Image: antonlarichev/short-app
Image ID: docker-pullable://antonlarichev/short-app@sha256:ecf6b7afbfc7b40b27516953c5dffc7325d5fe95ce811f43faa064ed2c86dcd9
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Sun, 22 Jun 2025 16:30:39 +0300
Ready: True
Restart Count: 0
Limits:
cpu: 500m
memory: 128Mi
Requests:
cpu: 500m
memory: 128Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-jr4c4 (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-jr4c4:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Guaranteed
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 40m default-scheduler Successfully assigned default/short-app to minikube
Warning Failed 40m kubelet Failed to pull image "antonlarichev/short-app": Error response from daemon: Get "https://registry-1.docker.io/v2/": tls: received record with version 857 when expecting version 303
Warning Failed 40m kubelet Error: ErrImagePull
Normal BackOff 40m kubelet Back-off pulling image "antonlarichev/short-app"
Warning Failed 40m kubelet Error: ImagePullBackOff
Normal Pulling 40m (x2 over 40m) kubelet Pulling image "antonlarichev/short-app"
Normal Pulled 40m kubelet Successfully pulled image "antonlarichev/short-app" in 14.328s (14.328s including waiting). Image size: 109145336 bytes.
Normal Created 40m kubelet Created container: short-app
Normal Started 40m kubelet Started container short-appУже ближе к концу виднеется поле Events, в котором описаны все операции и ошибки, которые могли произойти во время сборки. Тут можно заметить, что первые несколько операций прошли с ошибкой и не получилось сразу стянуть с registry валидные данные. Потом уже только после бэк-оффа произошёл пуллинг.
Так же мы можем проинспектировать и сервис. Тут уже меньше информации по айтему, но всё же тут указаны открытые порты, тип, имя и остальные параметры, по которым можно определить точки доступа для запроса
$ kubectl describe service short-app-port
Name: short-app-port
Namespace: default
Labels: <none>
Annotations: <none>
Selector: components=frontend
Type: NodePort
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.110.44.54
IPs: 10.110.44.54
Port: <unset> 3000/TCP
TargetPort: 80/TCP
NodePort: <unset> 31200/TCP
Endpoints: 10.244.0.3:80
Session Affinity: None
External Traffic Policy: Cluster
Internal Traffic Policy: Cluster
Events: <none>Работа с объектами
Императивный подход
Если нам нужно что-то быстро протестировать или изменить быстро в кластере, то можно воспользоваться императивным подходом и накатить изменения в архитектуру через командную строку командой
kubectl run my-pod --image=antonlarichev/short-app --labels="component=backend"Командой delete мы можем удалить ненужный нам Pod
$ kubectl delete pod my-pod
pod "my-pod" deletedИспользовать такой подход на настоящей инфраструктуре нельзя, так как эта команда останется только в истории наших команд в терминале и не более
Обновление объектов
В K8s доступно лёгкое обновление наших сервисов посредством изменения конфигурации
Проверим, что у нас остался старый сервис и его Image имеет старый формат
$ kubectl describe pods short-app
IPs:
IP: 10.244.0.4
Containers:
short-app:
Container ID: docker://da7564c24bc48ff4e841296ef9be550a128a1ebce36c5b1730dc01a3caf860d0
Image: antonlarichev/short-app
Image ID: docker-pullable://antonlarichev/short-app@sha256:ecf6b7afbfc7b40b27516953c5dffc7325d5fe95ce811f43faa064ed2c86dcd9
Port: 80/TCPЗаменим на другое изображение
pod.yml
spec:
containers:
- name: short-app
image: antonlarichev/short-apiПереприменим команду apply и в наш планировщик попадёт задача об изменении изображения в поде
$ kubectl apply -f .
service/short-app-port unchanged
pod/short-app configuredИ теперь можно опять запросить описание пода. Тут описаны все ивенты, которые произошли с ним. Перед обновлением изображения, под был убит, чтобы стянуть новый image и запустить заново контейнер внутри пода
Image так же поменялся на api
$ kubectl describe pods short-app
Containers:
short-app:
Container ID: docker://da7564c24bc48ff4e841296ef9be550a128a1ebce36c5b1730dc01a3caf860d0
Image: antonlarichev/short-api
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7m14s default-scheduler Successfully assigned default/short-app to minikube
Normal Pulling 7m13s kubelet Pulling image "antonlarichev/short-app"
Normal Pulled 6m59s kubelet Successfully pulled image "antonlarichev/short-app" in 14.64s (14.64s including waiting). Image size: 109145336 bytes.
Normal Created 6m59s kubelet Created container: short-app
Normal Started 6m59s kubelet Started container short-app
Normal Killing 4m9s kubelet Container short-app definition changed, will be restarted
Normal Pulling 4m9s kubelet Pulling image "antonlarichev/short-api"
Обновление происходит следующим образом:
- Мы применили в первый раз конфигурацию
- Kube API по metadata сначала пошёл искать существующий под, ничего не нашёл и создал новый под с нашей описанной конфигурацией
- Изменили конфигурацию и поменяли в ней, например,
image - Применили новую конфигурацию
- Новая конфигурация попала в Kube. Он по metadata понял, что такой pod уже существует. Далее он сравнивает изменения, которые произошли в конфигурации и применяет эти изменения для выделенного пода

Однако, у обновлений есть некоторые ограничения. Например, мы не можем изменить containerPort и должны будем завязаться на заранее определённом порту, либо переподнимать отдельно этот под, чтобы изменения вступили в силу
pod.yml
ports:
- containerPort: 81$ kubectl apply -f .
service/short-app-port unchanged
The Pod "short-app" is invalid: spec: Forbidden: pod updates may not change fields other than `spec.containers[*].image`,`spec.initContainers[*].image`,`spec.activeDeadlineSeconds`,`spec.tolerations` (only additions to existing tolerations),`spec.terminationGracePeriodSeconds` (allow it to be set to 1 if it was previously negative)
core.PodSpec{
Volumes: {{Name: "kube-api-access-drpmm", VolumeSource: {Projected: &{Sources: {{ServiceAccountToken: &{ExpirationSeconds: 3607, Path: "token"}}, {ConfigMap: &{LocalObjectReference: {Name: "kube-root-ca.crt"}, Items: {{Key: "ca.crt", Path: "ca.crt"}}}}, {DownwardAPI: &{Items: {{Path: "namespace", FieldRef: &{APIVersion: "v1", FieldPath: "metadata.namespace"}}}}}}, DefaultMode: &420}}}},
InitContainers: nil,
Containers: []core.Container{
{
... // 3 identical fields
Args: nil,
WorkingDir: "",
Ports: []core.ContainerPort{
{
Name: "",
HostPort: 0,
- ContainerPort: 80,
+ ContainerPort: 81,
Protocol: "TCP",
HostIP: "",
},
},
EnvFrom: nil,
Порты можно не указывать. K8s автоматически выводит наружу открытые порты. Однако указание портов является хорошей практикой для ведения ясной конфигурации.
Deployments
Управление pods напрямую - это более низкоуровневый кейс использования k8s. Чаще всего такие изменения происходят через механизм deployments, который контролирует сразу несколько подов

- Эта сущность описывается, как
kind: Deloyment replicas- количество реплик этих деплойментов, которые будут дефолтно созданыselector- это селекторы, по которым деплой сможет определить поды, которыми он будет рулитьtemplate- это раздел, в который мы можем поместить шаблон пода, которым будет управлять деплой. Конкретно здесь находится полное описание сущности типаkind: Pod, т.е. интерфейс описанияtemplate=kind: Pod
app-deployment.yml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: short-app-demo
spec:
# количество реплик подов
replicas: 1
# селекторы, по которым будет происходить связывание с подами
selector:
matchLabels:
components: frontend
# шаблон, который описывает то, что мы хотим запустить
template:
# тут находится всё то же самое, что и в pod
metadata:
labels:
components: frontend
spec:
containers:
- name: short-app
image: antonlarichev/short-api
ports:
- containerPort: 81
resources:
limits:
memory: 128Mi
cpu: 500mИспользование Deployments
Поднимаем деплой
$ kubectl apply -f ./app-deployment.yml
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/short-app-demo-7fc4f85f64-dlqkn 0/1 OOMKilled 1 (11s ago) 17s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 24h
service/short-app-port NodePort 10.105.253.142 <none> 3000:31200/TCP 21h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/short-app-demo 0/1 1 0 17s
NAME DESIRED CURRENT READY AGE
replicaset.apps/short-app-demo-7fc4f85f64 1 1 0 17sИ теперь после вывода пода, у нас появляется наше приложение с уникальным идентификатором
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
short-app-demo-7fc4f85f64-dlqkn 0/1 CrashLoopBackOff 4 (23s ago) 2m12sТак же мы можем вывести сущность deployment.apps, которая будет нам отображать наши деплои. Она является более высокоуровневой по отношению к pod.
$ kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
short-app-demo 0/1 1 0 3h19mЕсли мы запросим описание нашего деплоя, то тут мы увидим подробную информацию по его контейнерам и портам, а так же количеству реплик, которые созданы для определённого приложения
$ kubectl describe deployments.apps
OldReplicaSets: <none>
NewReplicaSet: short-app-demo-7fc4f85f64 (1/1 replicas created)
Events: <none>Теперь приложение работает ровно так же, как и раньше, когда мы его поднимали через pod.
Масштабирование Deployments
Основным преимуществом использования Deplyment по отношению к поднятию Pod является возможность простого масштабирования сервисов
Работа с подами
Изменим немного нашу конфигурацию деплоёмента и поменяем там изображение
spec:
containers:
- name: short-app
image: antonlarichev/short-apiДалее применим его ещё раз
$ kubectl apply -f ./app-deployment.yml
deployment.apps/short-app-demo configuredЕсли успеть быстро вывести все поды, то мы заметим, что у нас будет сразу несколько подов одного нашего сервиса.
Сейчас происходит безопасная замена одного пода на другой и старый pod k8s удалит, когда новый pod перейдёт в статус Running
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
short-app-demo-6f486d58b9-px5dm 1/1 Running 0 27s
short-app-demo-7fc4f85f64-cdr6k 0/1 ContainerCreating 0 1sТеперь попробуем изменить порт, который не удалось изменить в старом случае, когда мы работали только с подом
template:
# тут находится всё то же самое, что и в pod
metadata:
labels:
components: frontend
spec:
containers:
- name: short-app
image: antonlarichev/short-app
ports:
- containerPort: 3000Далее переприменяем конфиг и при вызове описания подов деплоя, мы получим информацию о том, что под запущен на новом порту
$ kubectl apply -f ./old/app-deployment.yml
deployment.apps/short-app-demo configured
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
short-app-demo-745dcbb6cc-87v55 1/1 Running 0 10s
$ kubectl describe deployments.apps
Pod Template:
Labels: components=frontend
Containers:
short-app:
Image: antonlarichev/short-app
Port: 3000/TCP
Host Port: 0/TCPРабота с репликами
Сейчас нам стоит почистить деплой перед тем как начать работать с выделением новых ресурсов.
$ kubectl delete deployments.apps short-app-demo
deployment.apps "short-app-demo" deletedА теперь заменим количество процессорных мощностей с 500 микропроцессоров (50% загрузки процессора) до 100 (10% загрузки), а так же увеличим количество реплик с 1 до 5 штук
app-deployment.yml
spec:
replicas: 5
selector:
matchLabels:
components: frontend
template:
metadata:
labels:
components: frontend
spec:
containers:
- name: short-app
image: antonlarichev/short-app
ports:
- containerPort: 3000
resources:
limits:
memory: 128Mi
cpu: 100mИ теперь у нас мгновенно стало доступно 5 реплик нашего приложения. Количество необходимых реплик в конфиге мы можем менять на лету в зависимости от наших потребностей (включая автоматическую подстройку).
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
short-app-demo-665974dd9-nz6lx 1/1 Running 0 10s
short-app-demo-665974dd9-p9sh9 1/1 Running 0 10s
short-app-demo-665974dd9-r7bmw 1/1 Running 0 10s
short-app-demo-665974dd9-rt7n2 1/1 Running 0 10s
short-app-demo-665974dd9-vsc4m 1/1 Running 0 10s
$ kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
short-app-demo 5/5 5 5 23sОбновление Image
Представим такую ситуацию:
- у нас есть
app-deployment.ymlс сервисом типаDeployment - в нём используется
imageс тегомlatest(как сейчасantonlarichev/short-app:latest) - нам нужно обновить образ, который соответствует этому тегу (прошлый image с тегом latest и залили новый с тем же самым тегом)
Так как deployment остаётся неизменным, то применение apply на конфиге не даст никакого эффекта и новый image не будет загружен.
Неправильный вариант
Первый вариант, который является неверным - это удаление деплоймента и пересоздание сервиса
kubectl delete deployments.apps short-app-demo
kubectl apply -f app-deployment.ymlПравильный вариант
Самым верным вариантом для обновления изображения в кубере - это будет использование изображения Docker не с тегом latest, а с определённой версией

Тогда команда apply будет применяться, так как мы изменили изображение в самом конфиге
spec:
containers:
- name: short-app
image: antonlarichev/short-app:v1.0kubectl apply -f app-deployment.ymlRollout
Команда rollout предоставляет доступ к…
История изменений
Группа history позволяет получить доступ к определённым операциям в сервисах deployment, daemonset, statefulset. Конкретно тут мы можем взглянуть на историю дейплоймента определённого сервиса.
В истории у нас отображается номер ревизии и причина изменения, которую мы можем указать командой после применения конфига
$ kubectl rollout history deployment short-app-demo
deployment.apps/short-app-demo
REVISION CHANGE-CAUSE
1 <none>
2 <none>Сейчас для примера изменим image ад-хоком в деплойменте
kubectl set image deployment.apps/short-app-demo short-app=antonlarichev/short-app:latest И количество элементов в истории изменится
$ kubectl rollout history deployment short-app-demo
deployment.apps/short-app-demo
REVISION CHANGE-CAUSE
1 <none>
2 <none>
3 <none>Редеплой
И решением проблемы из прошлого урока, когда у нас изображение с тегом latest, так же может являться rollout
Установим последнюю сборку latest и установим параметр imagePullPolicy в Always, чтобы k8s всегда запрашивал новое изображение при перезапуске конфигурации
app-deployment.yml
spec:
containers:
- name: short-app
image: antonlarichev/short-app:latest
imagePullPolicy: AlwaysС помощью restart мы можем перезапустить деплоймент с новой конфигурацией
kubectl rollout restart deployment short-app-demo
rollout restartв качестве обновленияlatest- плохая практикаТакой подход работы с деплоями так же является опасным, потому что последняя сборка может содержать множество багов, а откат к предыдущей версии окажется невозможным. Поэтому лучшим вариантом так же останется обновление
imageчерез указание версий, чтобы была возможность сделать быстрый откат до нужной версии (v1.0→v1.1).
Работа с сетью
ClusterIP
Сейчас мы попробуем развернуть приложение подобного вида:
- У нас будет кластер с доступом в него по ingress-контроллеру
- Внутри будут крутиться по два инстанса наших сервисов, которые будут объеденены друг с другом по ClusterIP
- api будет связан с pgsql так же по clusterip

Тут нам понадобится NodePort, так как доступ по ip нам нужен будет внутри, чтобы туда не смогли постучаться снаружи

NodePort на production нам не нужен и доступ в сервисы по портам 80/443 по портам будет предоставлять Ingress
Сущность ClusterIP будет скрывать под собой любое количество нашего отдельного сервиса, тем самым объединяя их

Доступа к этой сущности извне не будет

Для проброса запросов нам понадобится отдельный Ingress сервис

Сам Ingress обеспечивает доступ по домену, позволяя безопасно предоставить доступ к системе

Пишем ClusterIP
Очистим перед началом все прошлые сервисы
kubectl delete deployments.apps short-app-demo
kubectl delete service short-app-portСоздаём полностью новое окружение, в котором будет наш деплой. Реплика сервисов будет только одна.
apiVersion: apps/v1
kind: Deployment
metadata:
name: short-app-deployment
spec:
replicas: 1
selector:
matchLabels:
components: frontend
template:
metadata:
labels:
components: frontend
spec:
containers:
- name: short-app
image: antonlarichev/short-app:v1.0
ports:
- containerPort: 80
resources:
limits:
memory: "128Mi"И поднимем новый тип сервиса ClusterIP, который будет доступен по 80 порту и будет содержать в себе (по селекторам) компоненты frontend
app-service.yml
# тут будет просто v1, так как мы работаем с сервисом
apiVersion: v1
kind: Service
metadata:
name: short-app-clusterip
spec:
# поменяем тип
type: ClusterIP
ports:
# значение порта соответствует тому, что задано в спеке контейнеров приложения фронта
- port: 80
protocol: TCP
selector:
components: frontendДля запуска на маке потребовалось добавить
targetPort: 3000в объект вместе сport: 80
Применим обе конфигурации
kubectl apply -f ./app-deployment.yml
kubectl apply -f ./app-service.ymlИ теперь из-за отсутствия NodePort мы потеряли доступ к нашим сервисам. Через curl видно, что мы не сможем подключиться извне никак к нашим сервисам

Ingress
Ingress - это сервис, который предоставляет нам входную точку в наше приложение aka Gateway. Он обеспечивает вход по домену в наш кластер и управляет логикой распределения входящего трафика в зависимости от паттерна общения, url и хоста
Использование LoadBalancer заместо Ingress валидно в меньшем числе случаев, так как множество реализованных сервисов под Ingress как раз могут иметь под собой балансировку нагрузки через NGINX
Что происходит при входе клиента по домену:
- Как только пользователь переходит на наш домен
demo.test - Запрос переходит на связанный через DNS наш IP
- По этому IP располагается доступ к нашему кластеру
Требования:
- При переходе на
/мы должны получать наш фронт - При отправке запроса на
/api, он должен лететь на сервер
Типов Ingress контроллеров сразу несколько, но проще всего будет пользоваться NGINX, который сразу присутствует в k8s
Разные провайдеры могут по-разному реализовать этот контроллер: через AWS, Google Cloud и так далее

Конфигурация Ingress представляет из себя конфиг как и любого другого сервиса.
В самом дефолтном случае, у нас в minikube будет использоваться дефолтный NGINX, который и будет проксировать все наши запросы

Но если мы развернём нашу конфигурацию, например, в Google Cloud, то он добавит от себя ещё объект балансировщика, который будет так же обрабатывать и пропускать через себя запросы

По-сути для реализации полного доступа к нашей системе, нам нужно будет только поднять ClusterIP (для общения сервисов внутри кластера и обеспечения корневого доступа сразу ко всем сервисам под этим IP) и Ingress (для Gateway доступа)
Подготовка minikube
Контроллер Ingress доступен в minikube через аддоны, которые мы можем дополнительно установить
Включение ingress
Выведем список аддонов
minikube addons listИ тут отображён список включенных и выключенных аддонов

Включим аддон ingress. У нас скачается аддон ingress-nginx, после установки которого будет доступны наши сервисы по localhost ip 127.0.0.1
minikube addons enable ingressСоздание локального домена
Сначала получим актуальный ip нашего minikube
$ minikube ip
192.168.49.2Дальше нам нужно будет поднять отдельный домен для разработки внутри нашего ПК
sudo nvim /etc/hostsИ добавим строку ip domain в нашу конфигурацию хостов
Желательно в наименовании домена добавить
.dev,.testили использоватьlocalhost, чтобы форсированно не ловить редиректы наhttpsот хромиумных браузеров
192.168.49.2 demo.test
Для запуска на маке потребовалось поменять на
127.0.0.1 localhost demo.test
Настройка Ingress
Далее опишем Ingress контроллер в виде конфигурации k8s
ingress.yml
# используем последнюю версию API для Ingress сервисов
apiVersion: networking.k8s.io/v1
# тут напрямую укажем Ingress
kind: Ingress
metadata:
name: myingress
# annotations представляет собой дополнительные конфигурации контроллера
# конкретно тут будут храниться дополнительные конфигурации самого NGINX
annotations:
# этой настройкой мы добавляем базовый url
nginx.ingress.kubernetes.io/add-base-url: "true"
spec:
# имя класса ingress контроллера будет содержать nginx
ingressClassName: nginx
# описание правил редиректов
rules:
- host: demo.test # корневой домен, с которого нужно обрабатывать запросы
http:
# правила путей в виде массива
paths:
- pathType: Prefix # смотрим на префикс запроса
path: "/" # при попадании на "/" корень домена
backend: # то, куда мы перенаправляем
# перенаправим запрос на сервис
service:
# с ClusterIP по имени (из app-service.yml)
name: short-app-clusterip
# и с портом 80
# (который указан как прослушиваемый в app-service.yml)
port:
number: 80И получаем объект ingress
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
myingress nginx demo.test 80 9sТеперь по домену demo.test у нас будет доступен фронт без обращения по ip и порту

Volumes
Deployment базы
Так будет выглядеть деплой PGSQL. Тут мы укажем конкретную версию PGSQL и задефайним выходящий наружу порт 5432
postgres-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
components: postgres
template:
metadata:
labels:
components: postgres
spec:
containers:
- name: postgres
image: postgres:16.0
ports:
- containerPort: 5432
resources:
limits:
memory: "500Mi"
cpu: "300m"И всё под собой закрывать будет ClusterIP с коннектом по порту 5432 из деплоя и связыванием по компоненту указанным, так же в деплое postgres
postgres-service.yml
apiVersion: v1
kind: Service
metadata:
name: postgres-clusterip
spec:
type: ClusterIP
ports:
- port: 5432
protocol: TCP
selector:
components: postgresEnv
Переменные окружения передаются в параметр env отдельного контейнера. Это, преимущественно, публичные данные, которые не являются секретами.
Представляют собой массив объектов с именем переменной и значением.
postgres-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
components: postgres
template:
metadata:
labels:
components: postgres
spec:
containers:
- name: postgres
image: postgres:16.0
ports:
- containerPort: 5432
# env переменные
env:
- name: POSTGRES_DB
value: demo
- name: POSTGRES_USER
value: demo
- name: POSTGRES_PASSWORD
value: demo
resources:
limits:
memory: "500Mi"
cpu: "300m"Запускаем конфиг
kubectl apply -f ./old/postgres-deployment.yml
kubectl apply -f ./old/postgres-service.ymlPort forwarding
Сейчас нам нужно будет напрямую поработать с нашей базой данных через
Для этого нам нужно будет прокинуть порт из pod наружу на наш компьютер. Сделать это можно с помощью механизма port-forwarding
$ kubectl port-forward pods/postgres-deployment-5c6b78897c-cbqgb 5432:5432
Forwarding from 127.0.0.1:5432 -> 5432
Forwarding from [::1]:5432 -> 5432Далее, с помощью любого интерфейса, мы сможем подключиться извне к нашей БД

Далее создаём таблицу Link с нужными для нашего API сервиса полями
CREATE TABLE "Link" (
"id" SERIAL NOT NULL,
"url" TEXT NOT NULL,
"hash" TEXT NOT NULL,
CONSTRAINT "Link_pkey" PRIMARY KEY ("id")
);
Проблема
Перезапустим наш деплой с postgres
kubectl rollout restart deployment postgres-deployment
kubectl port-forward pods/postgres-deployment-fd49bc75-qdbqn 5432:5432И можно заметить, что все данные из нашей базы пропали, так как под с базой пересоздался

Далее нам нужно будет создать персистентное хранилище для нашей базы
Volumes
Volume в Docker и k8s - это немного разные сущности
Сейчас данные, которые генерирует контейнер, хранятся прямо рядом с сервисом внутри контейнера. Поэтому при перезапуске PGSQL у нас терялись данные базы.

Для решения проблемы в k8s существуют данные объекты:
- Volume
- Persistent Volume
- Persistent Volume Claim

Volume
Volume - это контейнер, который находится рядом с контейнером сервиса. Он сможет сохранить данные после перезагрузки, но потеряет их, если мы пересоздадим под.

Плюсом данного Volume является возможность шарить данные между несколькими контейнерами внутри одного пода
Persistent Volume
Persistent Volume (PV) - это объект, который так же находится внутри k8s, но с той разницей, что он уже находится вне pod и к нему может подключиться pod после перезагрузки или обновления

Такой подход позволяет создать Stateless Pod, то есть сколько бы раз нам не пришлось перезапустить Pod, он всегда сможет восстановить своё состояние, так как его данные находятся вне его контейнера.
Persistent Volume Claim
Persistent Volume Claim (PVC) - это сущность, которая предоставляет Persisted Volume хранилище для пода.
Pod запрашивает у PVC хранилище на 100 гб, которое второй ему должен предоставить по запросу

Мы можем создать несколько статичных PV на определённое количество пространства. Это Static PV.
Если Pod потребует Volume другого размера, то PVC создасть Dynamic PV на нужное количество места для пода.
Персистентность
Мы задеплоили pod с нашим контейнером. Внутри этого контейнера хранятся данные, которые нужны для работы сервиса.

После перезапуска pod, его внутренние данные, с которыми он работал, стираются

И новый pod теперь не буедт работать ни с какими старыми данными

Первое возможное решение этой проблемы - создание Persisted Volume. Новый объект, который находится вне Pod и сохраняет его данные между пересозданием основного сервиса.

Теперь после пересоздания Pod, его данные не будут теряться, а новый Pod с нашим сервисом будет тянуть старые данные из PV

Теперь новый Pod работает так, как мы и ожидали

Но тут мы можем столкнуться с такой проблемой, что два разных инстанса нашего сервиса (например pgsql) могут тянуть данные из одного volume (т.е. данные будут шариться между подами)
Доступ к данным БД должна иметь только один инстанс БД, иначе это приведёт к конфликтам и коллизиям в итоговых данных

Для правильной работы PV с pgsql, нам нужно будет под каждую реплику pgsql поднять свой PV. Иначе, если одна база запишет данные, а другая их прочитает и увидит неконсистентность, то наш сервис с БД ляжет.
В целом, когда мы работаем с PV, нам нужно всегда понимать и держать в голове, сколько разных инстансов Pod будет работать с этим PV, чтобы не иметь проблем с конфликтами данных.
PersistentVolumeClaim
Опишем конфигурацию сервиса PVC, который должен выдавать на запрос пода пространство равное 1 гигабайту памяти под один сервис
postgres-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pvc
spec:
resources:
requests:
storage: 1Gi # пространство 1ГБ
accessModes:
- ReadWriteOnce # использовать может только один инстанс postgresРежимов доступа к сервису у нас сразу несколько:

StorageClass
Когда мы описываем PVC, то кубер (локально minikube) сразу определяет себе пространство, которое он будет занимать и при запросе от сервиса выделить из этого пространства кусочек для пользования сервисами

Но когда мы говорим про удалённый запуск, у нас уже реализации будут немного отличаться друг от друга.
В облаке кубер без конфигурации не имеет представления, откуда брать пространство, которое нужно выделить для сервиса. Однако облачные провайдеры преконфигурируют кубер так, чтобы он понимал, откуда нужно брать пространство для подов.

Узнать, какой тип пространства у нас выделен для k8s на данном устройстве, можно через:
kubectl get storageclasses.storage.k8s.ioStorageClass - это обозначение того, как мы должны взаимодействовать с определённым пространством. Он взаимодействует с разными типами пространств с помощью плагинов.

Параметры, которые выводит нам команда:
-
NAME
-
имя
-
PROVISIONER - поставщик пространства (плагин)
-
RECLAIM POLICY - метод восполнения пространства обратно (когда PVC удалён)
-
VOLUME BINDING MODE - ивент, когда выделяется пространство (Immediate - выделяется сразу)
-
ALLOW VOLUME EXPANSION - доступно ли расширение пространства
-
AGE - возраст пространства

За определение типа пространства в конфигурации PVC отвечает поле storageValueClass. В нашей локальной конфигурации достаточно оставить дефолтное значение, которое задано по умолчанию.
Mount в deployment
Дополним конфигурацию деплоя полями volumes и volumeMounts, в которых опишем сами пространства и их связи
postgres-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
components: postgres
template:
metadata:
labels:
components: postgres
spec:
containers:
- name: postgres
image: postgres:16.0
ports:
- containerPort: 5432
env:
- name: POSTGRES_DB
value: demo
- name: POSTGRES_USER
value: demo
- name: POSTGRES_PASSWORD
value: demo
resources:
limits:
memory: "500Mi"
cpu: "300m"
# описываем точки монтирования в поде, которые будем маунтить в volume
volumeMounts:
# имя пространства, куда мы будем монтироваться
- name: postgres-data
# точка монтирование
mountPath: /var/lib/postgresql/data
# наименование подпапки, которая будет хранить данные из точки монтирования в volume
subPath: postgres
# тут мы определяем список наших volumes
volumes:
# сссылаемся на pvc сервис, который будет выделять volumes
- name: postgres-data
persistentVolumeClaim:
claimName: postgres-pvcСейчас в postgres есть баг, что без созданной
subPath(т.е. в корне volume) стягивание данных работать не будет. Поэтому нам нужно указать подпапкуsubPath, куда будут помещены данные изmountPath.
Далее поднимаем PVC и обновляем деплой postgres
kubectl apply -f ./old/postgres-pvc.yml
kubectl apply -f ./old/postgres-deployment.ymlИ глянем на созданные PVC в системе
kubectl get persistentvolumeclaims
Проверка работы
Применяем ещё раз скрипт создания таблицы из прошлого урока
Рестартим сервис и подключаемся к нему
kubectl rollout restart deployment postgres-deployment
kubectl port-forward pods/postgres-deployment-65b9746778-vjpfq 5432:5432Теперь можно заметить, что наш сервис сохранил свои данные и не потерял созданную таблицу

Секреты
Секреты
Дефолтно, мы описали переменные окружения прямо внутри наших конфигураций. Это крайне плохая практика. Все эти секьюрные данные полетят прямо к нам в гит и могут быть подспорьем для свободного доступа в нашу систему.

Для решения проблем с безопасным хранением данных, нужно использовать механизм секретов, которые заставят нас хранить нужные для подключения данные локально

Императивный подход
Есть несколько типов секретов:
-
generic
-
любой
-
tls - ключи / сертификаты
-
docker-registry - для конфигурации docker registry
Так же есть ещё несколько типов, которые больше нужны для конфигурации прода
Командой мы будем создавать секрет дженерик-типа
Мы можем создать
- plain-строку с переменными, которые нужно передать к нам
- ссылкой на файл, в котором хранятся переменные
kubectl create secret generic pg-secret --from-literal PASSWORD=demoИ получить созданные секреты для подов можем командой get
$ kubectl get secrets
NAME TYPE DATA AGE
pg-secret Opaque 1 11sИ описание сохранённых переменных окружения
$ kubectl describe secrets
Name: pg-secret
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
PASSWORD: 4 bytesБезопасность секретов
К сожалению, сохранение секретов напрямую не является безопасной практикой, так как несмотря на то, что они хранятся где-то в кластере, они всё равно лежат в определённом месте в base64
Мы можем напрямую получить наш секрет сохранённый в кубере с помощью определения go-template на получение данных
$ kubectl get secrets pg-secret --template={{.data.PASSWORD}}
ZGVtbw==%Но по-факту это просто окажется base64 зашифрованная строка
$ kubectl get secrets pg-secret --template={{.data.PASSWORD}} | base64 -D
demo%Секрет в кубере не является панацеей и сохранение секретов в другие сервисы так же не улучшат ситуацию. Лучший вариант защиты - чёткое разграничение зон ответственности и доступа к кубер-кластеру.
Конфиг секрета
Далее мы можем описать хранение наших секретов декларативным образом через создание сервиса секретов.
Переведём сначала ручками наш секрет из строки demo в base64 строку
$ echo -n demo | base64
ZGVtbw==Опишем сервис типа Secret, в который поместим наши данные зашифрованные в формате base64
postgres-secret.yml
apiVersion: v1
kind: Secret
metadata:
name: postgres-secret
type: Opaque
data:
POSTGRES_DB: ZGVtbw==
POSTGRES_USER: ZGVtbw==
POSTGRES_PASSWORD: ZGVtbw==Далее нам нужно будет применить эти секреты из сервиса секретов
postgres-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
components: postgres
template:
metadata:
labels:
components: postgres
spec:
containers:
- name: postgres
image: postgres:16.0
ports:
- containerPort: 5432
# блок переменных окружения
env:
- name: POSTGRES_DB
# указываем, откуда хотим подтянуть секрет
valueFrom:
# описываем референс, откуда тянем секрет
secretKeyRef:
# указываем имя сервиса, откуда возьмём секрет
name: postgres-secret
# имя секрета
key: POSTGRES_DB
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: postgres-secret
key: POSTGRES_USER
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: POSTGRES_PASSWORD
resources:
limits:
memory: "500Mi"
cpu: "300m"
volumeMounts:
- name: postgres-data
mountPath: /var/lib/postgresql/data
subPath: postgres
volumes:
- name: postgres-data
persistentVolumeClaim:
claimName: postgres-pvcИ далее создаём наш сервис секретов и переприменяем деплой постгреса
$ kubectl apply -f ./old/postgres-secret.yml
$ kubectl apply -f ./old/postgres-deployment.ymlУпражнение - пишем второй сервис
Дополняем нашу архитектуру проекта:
- добавим сюда два сервиса секретов (api и postgres)
- опишем PersistentVolume для сервиса postgres

Описываем отдельно сервис бэкэнда, который будет выглядеть подобно фронтовому
api-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: short-api-deployment
spec:
replicas: 1
selector:
matchLabels:
components: backend
template:
metadata:
labels:
components: backend
spec:
containers:
- name: short-api
image: antonlarichev/short-api:v1.0
ports:
- containerPort: 3000
resources:
limits:
memory: "128Mi"
cpu: "100m"Теперь нужно описать ClusterIP, который под собой скроет все сервисы нашего бэкэнда
api-service.yml
apiVersion: v1
kind: Service
metadata:
name: short-api-clusterip
spec:
type: ClusterIP
ports:
- port: 3000
protocol: TCP
selector:
components: backendИ отдельно обновим тег приложения фронта до последней версии
app-deployment.yml
image: antonlarichev/short-app:v1.4Упражнение - секрет для сервиса
Сейчас нам нужно собрать передать переменную окружения DATABASE_URL в наш api-service, которая будет собой представлять ссылку на подключение к postgres
Из особенностей можно выделить:
- у нас все параметры определены как
demo - ссылкой на подключение (
url) будет являться наименование сервиса ClusterIP нашего postgres сервиса (metadata.nameизpostgres-service.yml)
nameClusterIP сервиса автоматически попадает в DNS k8s и позволяет разрезолвить ip этого сервиса
# шаблон строки подключения
postgresql://user:password@url:5432/db
# реализация в нашем кластере
postgresql://demo:demo@postgres-clusterip:5432/demo
Переводим строку подключения в base64
echo -n postgresql://demo:demo@postgres-clusterip:5432/demo | base64Опишем секрет, который будет хранить ссылку на подключение к нашей БД
api-secret.yml
apiVersion: v1
kind: Secret
metadata:
name: short-api-secret
type: Opaque
data:
DATABASE_URL: cG9zdGdyZXNxbDovL2RlbW86ZGVtb0Bwb3N0Z3Jlcy1jbHVzdGVyaXA6NTQzMi9kZW1vДальше остаётся только передать сюда переменную с URL для подключения к БД
api-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: short-api-deployment
spec:
replicas: 1
selector:
matchLabels:
components: backend
template:
metadata:
labels:
components: backend
spec:
containers:
- name: short-api
image: antonlarichev/short-api:v1.0
ports:
- containerPort: 3000
resources:
limits:
memory: "512Mi"
cpu: "200m"
env:
- name: DATABASE_URL
valueFrom:
secretKeyRef:
name: short-api-secret
key: DATABASE_URLОтладка проекта
Поднимем сервисы бэка и секретов
$ kubectl apply -f ./old/api-secret.yml
secret/short-api-secret created
$ kubectl apply -f ./old/api-deployment.yml
deployment.apps/short-api-deployment createdСобрать логи можно командой logs
$ kubectl logs pods/postgres-deployment-5bfbcc7857-kpfkz
PostgreSQL Database directory appears to contain a database; Skipping initialization
2025-09-03 14:52:43.357 UTC [1] LOG: starting PostgreSQL 16.0 (Debian 16.0-1.pgdg120+1) on aarch64-unknown-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit
2025-09-03 14:52:43.357 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
2025-09-03 14:52:43.357 UTC [1] LOG: listening on IPv6 address "::", port 5432
2025-09-03 14:52:43.358 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2025-09-03 14:52:43.359 UTC [29] LOG: database system was shut down at 2025-09-03 14:51:43 UTC
2025-09-03 14:52:43.361 UTC [1] LOG:
$ $kubectl logs pods/short-api-deployment-57657f58d6-85f5d
> short-api@0.0.1 start
> nest start
[Nest] 31 - 09/03/2025, 4:21:56 PM LOG [NestFactory] Starting Nest application...
[Nest] 31 - 09/03/2025, 4:21:56 PM LOG [InstanceLoader] DatabaseModule dependencies initialized +294ms
[Nest] 31 - 09/03/2025, 4:21:56 PM LOG [InstanceLoader] AppModule dependencies initialized +6ms
[Nest] 31 - 09/03/2025, 4:21:57 PM LOG [RoutesResolver] AppController {/api}: +204ms
[Nest] 31 - 09/03/2025, 4:21:57 PM LOG [RouterExplorer] Mapped {/api, GET} route +90ms
[Nest] 31 - 09/03/2025, 4:21:57 PM LOG [RouterExplorer] Mapped {/api/:hash, GET} route +2ms
[Nest] 31 - 09/03/2025, 4:21:57 PM LOG [RouterExplorer] Mapped {/api, POST} route +4ms
[Nest] 31 - 09/03/2025, 4:21:57 PM LOG [RouterExplorer] Mapped {/api/:id, DELETE} route +2ms
[Nest] 31 - 09/03/2025, 4:22:00 PM LOG [NestApplication] Nest application successfully started +3595ms
Изменение ingress
Сейчас добавим префикс /api, который будет перенаправлять запросы на имя short-api-clusterip, которое под собой крутит нашу апишку
ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myingress
annotations:
nginx.ingress.kubernetes.io/add-base-url: "true"
spec:
ingressClassName: nginx
rules:
- host: demo.test
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: short-app-clusterip
port:
number: 80
- pathType: Prefix
path: "/api"
backend:
service:
name: short-api-clusterip
port:
number: 3000Далее применяем изменения в ингрессе
kubectl apply -f ./ingress.ymlИ все три сервиса теперь доступны извне, работают и взаимодействуют друг с другом. Проверить можно посредством вывода сервиса на 127.0.0.1 через minikube tunnel

Эксплуатация
Dashboard
Мы можем вывести общий дашборд по всем развёрнутым локально проектам через плагин миникуба
minikube dashboardТут будет находиться вся информация о кластере с: объектами, загрузкой, джобами и всеми остальными объектами

Так же тут мы можем ручками заскейлить сервис, перезапустить, переименовать или удалить

Менять конфигурации, обновлять изображения или просто дополнять конфиг через dashboard не стоит, так как изменения инфры он не сохранит
Подключение к Pod
Подключение к контейнеру внутри k8s происходит аналогично тому, как это происходит в Docker
Такая команда позволит нам прейти в интерактивный режим работы с контейнером
kubectl exec -it short-api-deployment-57657f58d6-85f5d -- /bin/bashЭта команда позволит нам прямо внутри проверить все элементы, которые могут вызвать у нас вопросы

Попадаем мы в сам контейнер по достаточно сложному механизму, который реализован в k8s. Наш kubectl не может напрямую залезть в контейнер.
Порядок выполнения команды exec:
kubectlвызывает API, которое находится в мастер ноде- Мастер нода ищет контейнер и делегирует задачу из
kubectlвkubeletнайденной ноды kubeletпередаёт задачу вcontainer runtimecontainer runtimeчерезkernel-runtimeпросит исполнить операцию над определённым контейнером внутри пода

ConfigMap
Представим такую ситуацию, что нам нужно подложить postgresql.conf файл, который будет детально описывать работу нашей базы, внутрь pod контейнера

ConfigMap - это отдельная сущность, которая позволяет подложить определённые данные внутрь нашего пода с помощью volume

Создадим конфиг с параметрами
demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
key: valueapi-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: short-api-deployment
spec:
replicas: 1
selector:
matchLabels:
components: backend
template:
metadata:
labels:
components: backend
spec:
containers:
- name: short-api
image: antonlarichev/short-api:v1.0
ports:
- containerPort: 3000
resources:
limits:
memory: "500Mi"
cpu: "200m"
env:
- name: DATABASE_URL
valueFrom:
secretKeyRef:
name: short-api-secret
key: DATABASE_URL
# опишем маунт для контейнера пространства test
volumeMounts:
- name: test
mountPath: /etc/test
readOnly: true
# пространства
volumes:
- name: test # имя пространства
# описываем тут карту конфигураций
configMap:
name: demo-configПрименим новые конфигурации
$ kubectl apply -f ./demo-config.yml
$ kubectl apply -f ./api-deployment.ymlВнутри пода создастся папка test с файлом key
$ kubectl exec -it short-api-deployment-57657f58d6-85f5d -- /bin/bash
$ cat /etc/test/key
valueRollout
Чтобы заставить смотреть за изменениями объектов k8s, мы можем передать флаг --watch
kubectl get pod --watchВ одном терминале запустим отслеживание подов, а в другом выведем ревизии и изменим деплой
kubectl rollout history deployment short-api-deployment
rollout имеет несколько объектов для отображения:
- history - история деплоев
- pause - остановить деплой
- restart - перезапустить деплой
- resume - продолжить деплой
- status - статус деплоя
- undo - отменить ревизию обновления

Чтобы отменить деплой, который мы только что сделали и вернуться на прошлую ревизию, мы можем воспользоваться undo и указать конкретную ревизию --to-revision
kubectl rollout undo deployment short-api-deployment --to-revision=2Это очень удобный вариант в том случае, когда мы сделали очень много новых деплоев, но откатывать каждый будет крайне неээфективно и можно точечно откатить нужный нам сервис
Однако этот механизм работает только с
deployment
Healthckeck
Healtcheck - это важный механизм для проверки жизни нашего сервиса, который позволит вовремя отследить то, что сервис упал и перезапустить его автоматически
В качестве чекера в k8s выступает Probe, который собирает пробы из пода и делает выводы о надобности рестарта
В k8s есть три основных чекера:
livenessProbe- проверяет жизнеспособность контейнера в течение его Running состоянияstartupProbe- проверяет поднятиеreadinessProbe- проверяет готовность контейнера к тому, чтобы он встал в строй (например, огромный jar, который сам по себе долго запускается внутри и нужно проверить его готовность отвечать)

Сначала попробуем изнутри пода отправить запрос на проверку - он должен вернуть нам какие-то данные и успешный запрос
$ kubectl exec -it short-api-deployment-57657f58d6-85f5d -- /bin/bash
$ curl http://localhost:3000/api
[{"id":64,"url":"https://ya.ru/","hash":"HRWtY"},{"id":65,"url":"https://vk.com/feed","hash":"9JLZy"},{"id":55,"url":"https://google.com","hash":"rAAtP"}]Нужно понимать тот момент, что мы можем проверить прошлую команду на ошибку через echo $?
$ cat d
<error> # ошибка
$ echo $?
1
$ cat .env
...
$ $echo $?
0Чтобы описать отправку запроса, нам нужно добавить определённый вид пробы и указать один из вариантов запросов:
exec- кастомный запрос, который мы реализуем сами описывая команду (будет запущен внутри pod)httpGet- внутренний механизм k8s, который подходит наименее всего, так как он совершается снаружи и нам нужно точно знать, где будет располагаться сервис в моменте времени (пулять запрос на определённый домен)
api-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: short-api-deployment
spec:
replicas: 1
selector:
matchLabels:
components: backend
template:
metadata:
labels:
components: backend
spec:
containers:
- name: short-api
image: antonlarichev/short-api:v1.0
ports:
- containerPort: 3000
resources:
limits:
memory: "500Mi"
cpu: "200m"
env:
- name: DATABASE_URL
valueFrom:
secretKeyRef:
name: short-api-secret
key: DATABASE_URL
volumeMounts:
- name: test
mountPath: /etc/test
readOnly: true
# healthcheck
livenessProbe:
exec: # выполняем
command: # команду
- curl
- --fail
- http://localhost:3000/api
# начальная задержка работы пробы
initialDelaySeconds: 30
# отправляем раз в 5 секунд
periodSeconds: 5
# допустимое количество ошибок перед рестартом
failureThreshold: 1
volumes:
- name: test
configMap:
name: demo-configNamespace
Что это?
Namespace (NS) - это область, в рамках которой у нас будут создаваться объекты
Список всех namespaces
•% ➜ kubectl get namespaces
NAME STATUS AGE
default Active 7d1h # тут располагаются сервисы без NS
ingress-nginx Active 4d3h # пространство для ingress
kube-node-lease Active 7d1h # предоставляет информацию о нодах
kube-public Active 7d1h # публичные данные о кубе, которая доступна без авторизации
kube-system Active 7d1h # тут запущены системные сервисы k8s
kubernetes-dashboard Active 23h # специфичное пространство minikube Получение списка подов по NS
$ kubectl get pods -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-5d59dccf9b-x46h8 1/1 Running 0 24h
kubernetes-dashboard-7779f9b69b-x6kqn 1/1 Running 0 24hС помощью конфигурации k8s, можно поменять контекст --current (default) на наш созданный
# переводим контекст на k8s dashboard
$ kubectl config set-context --current --namespace=kubernetes-dashboard
Context "minikube" modified.
# и теперь команды будут выводить поды из данного контекста
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-5d59dccf9b-x46h8 1/1 Running 0 24h
kubernetes-dashboard-7779f9b69b-x6kqn 1/1 Running 0 24h
# меняем контекст обратно
$ kubectl config set-context --current --namespace=defaultЗачем
Представим, что у нас достаточно большое количество различных и абсолютно не связанных друг с другом приложений и работать с таким массивом подов становится неудобно, потому что наши логи забиваются моментально

Было бы очень удобно, если бы по нашему запросу, мы могли бы скрывать часть приложений, которые относятся к другому продукту.
То есть поделить поды на:
- мониторинг
- сервис доставки
- сервис админки

NS позволяет нам решить проблемы:
- разделения зон ответственности приложения (разделение баз данных, мониторинга, различных приложений)
- избегания конфликтов названий (если команды могли назвать приложения одинаково)
- Dev и Prod среда (для маленьких проектов)
- Поделить ресурсы на окружения

Но тут мы можем столкнуться с проблемой, что доступ объектов одного неймспейса к объектам другого - будет отсутствовать
Доступ останется для сервисов, но там нужно будет в название сервиса добавить пространство <service>.namespace
Но за счёт такого ограничения, мы как раз и можем реализовать отдельные dev и prod среды

Ну и с помощью этой команды мы можем получить список объектов, которые не могут входить в пространства имён
kubectl api-resources --namespaced=false
Создание
AD-hoc
Создать пространство имён легко можно так же создать командой по аналогии с другими объектами
kubectl create namespace ...Конфигурация
Так выглядит простейший сервис пространства имён:
app-namespace.yml
apiVersion: v1
kind: Namespace
metadata:
name: my-namespaceПрименение
Подтверждаем создания пространства
kubectl apply -f app-namespace.ymlОстаётся только поднять объект в этом пространстве имён
Через команду
Первый вариант применения нужен для локальной и быстрой проверки работоспособности в разных пространствах, либо когда нам нужно один утилитарный сервис поднять для какого-либо пространства
kubectl apply -f ./app-deployment.yml -n my-namespaceЧерез IaC
Самый правильный и устойчивый вариант для прод деплоя
Добавляем один из наших деплоев в пространство имён (метаданные → namespace)
app-deployment.yml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: short-app-deployment
namespace: my-namespace И применяем этот деплой apply -f
Работа
Выводим список подов по нашему пространству имён
$ kubectl get pods -n my-namespace
NAME READY STATUS RESTARTS AGE
short-app-deployment-69885ccd89-tpdl5 1/1 Running 0 17sИ тут нужно уточнить, что наш старый деплой остался в глобальной области видимости и теперь у нас абсолютно два несвязанных между собой инстанса app-deployment запущено в разных пространствах имён

Удаление
Удалить дубликат деплоя можно стандартной командой с указанием пространства имён
⇡% ➜ kubectl delete deployments.apps -n my-namespace short-app-deployment
deployment.apps "short-app-deployment" deletedРазделение окружений
Мы можем применить такую команду сначала с env для дева, а потом для прода, чтобы иметь возможность протестировать работу всех наших сервисов
kubectl apply -f . -n dev-envЗнакомство с Helm
Зачем нужен
Проблема
- Повторы
В достаточно большом количестве мест у нас сейчас переиспользуются одни и те же значения по типу: компонентов, лейблов, портов

- Динамические значения
Так же переменные, которые могут меняться постоянно - их нам тоже придётся постоянно менять руками

- Зашифрованные данные хранятся открыто
Сейчас мы, в целом, в открытом виде храним все переменные окружения и секреты, которые не стоит выносить в репозиторий
- Самостоятельное управление релизами
spec:
containers:
- name: short-app
image: antonlarichev/short-app:v1.4Чем можно решить
С вышеописанными задачами справиться могут:
- ansible
- kubernetes
- другие шаблонизаторы с передачей данных в kubectl (например, Jinja, Nunchacks)
Однако:
- Ansible не заточен под работу с k8s
- Шаблонизаторы не заточены под работу с релизами и при
rollout undoоткатится вся система до прошлого релиза
Почему Helm?
-
Декларативность
-
Это
-
Поддерживает rollback и watch (следит за релизом и можно откатить любые части системы)
-
Имеет собственные плагины
Установка
Лучший способ - с помощью пакетного менеджера системы
brew install helmКомпоненты
CLI - это та часть, которая позволяет работать с нашими репозиториями, выкатывать релизы и работать с charts
Компоненты:
- Chart - пакет, содержащий описание ресурсов, необходимых для работы
- Repository - куда можно публиковать chart, чтобы делиться ими
- Release - пример Chart, которые работаете в кластере k8s
Chart состоит из:
- Meta-информации (зависимости)
- Values (значения, которые должны попасть в шаблоны, включая версию image, количества реплик и так далее)
- Templates (шаблон deployment, который нужно будет выкатить)
Механизм работы
У нас есть объект Chart, с которым работает CLI
CLI может сложить Chart в репозиторий, либо забрать оттуда его
После получения Chart (локально или из репы), у нас появляется возможность выкатить Chart на кластер
Далее Template заполняется нашими Values и мы получаем готовый конфиг, который улетает через kubectl в кластер
В кластере у нас хранится секрет с информацией о релизе. Если наш деплой упал или ушёл с ошибками, то он легко уйдёт в откат по информации из этого секрета.

Поиск charts
Добавление репозитория
Начально добавляем стабильный репозиторий с чартами. Таким же образом можно добавить приватный репозторий.
helm repo add stable https://charts.helm.sh/stable
helm repo updateПроверим, что репозиторий был добавлен
$ helm repo list
NAME URL
stable https://charts.helm.sh/stableПоиск
Поиск осуществляется таким образом
helm search repo mysql
Использование сторонних пакетов - это плохой вариант. Самый безопасный и стабильный - это написание собственного чарта, который будет подходить нашей системе и кластеру
Использование
Установка стороннего чарта происходит командой install
$ helm install stable/mysql --generate-name
WARNING: This chart is deprecated
NAME: mysql-1757409042
LAST DEPLOYED: Tue Sep 9 12:10:42 2025
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
MySQL can be accessed via port 3306 on the following DNS name from within your cluster:
mysql-1757409042.default.svc.cluster.local
To get your root password run:
MYSQL_ROOT_PASSWORD=$(kubectl get secret --namespace default mysql-1757409042 -o jsonpath="{.data.mysql-root-password}" | base64 --decode; echo)
To connect to your database:
1. Run an Ubuntu pod that you can use as a client:
kubectl run -i --tty ubuntu --image=ubuntu:16.04 --restart=Never -- bash -il
2. Install the mysql client:
$ apt-get update && apt-get install mysql-client -y
3. Connect using the mysql cli, then provide your password:
$ mysql -h mysql-1757409042 -p
To connect to your database directly from outside the K8s cluster:
MYSQL_HOST=127.0.0.1
MYSQL_PORT=3306
# Execute the following command to route the connection:
kubectl port-forward svc/mysql-1757409042 3306
mysql -h ${MYSQL_HOST} -P${MYSQL_PORT} -u root -p${MYSQL_ROOT_PASSWORD}Chart после скачивания сразу полетел в наш деплой
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql 0/1 ImagePullBackOff 0 2m25sПолучение информации
Для получения базовой информации о чарте, можем вызвать show chart, где будет и версия приложения, и описание, и основная мета-информация
$ helm show chart stable/mysql
apiVersion: v1
appVersion: 5.7.30
deprecated: true
description: DEPRECATED - Fast, reliable, scalable, and easy to use open-source relational
database system.
home: https://www.mysql.com/
icon: https://www.mysql.com/common/logos/logo-mysql-170x115.png
keywords:
- mysql
- database
- sql
name: mysql
sources:
- https://github.com/kubernetes/charts
- https://github.com/docker-library/mysql
version: 1.6.9Для получения полной информации о чарте нужно уже будет вызвать show all и нам выйдет полная ридмиха
helm show all stable/mysqlОчистка
Чтобы очистить чарт хельма, мы можем просто удалить деплой, который он вызвал
$ kubectl delete deployments.apps mysql-1757409042
deployment.apps "mysql-1757409042" deletedСоздание chart
Создадим базовую структуру Helm комадой create
helm create short-serviceИ примерно так будет выглядеть структура нового сервиса

Этот файл содержит базовую информацию по Helm-проекту и является входной точкой
Chart.yml
apiVersion: v2
name: short-serv
description: A Helm chart for Kubernetes
type: application
version: 0.1.0
appVersion: "1.16.0"Уже templates и values позволяют конфигурировать шаблоны
Файл values.yml содержит в себе данные для сборки чартов
Файл .helmignore хранит в себе всё то, что нам не нужно передавать в репозиторий с чартами. Работает по аналогии с .gitignore.
В charts располагаются зависимости
В templates располагаются сами шаблоны helm
Файл NOTES.txt содержит шаблон того, что мы хотим вывести человеку после завершения операции install
Шаблоны
Перенос deployment
Prerequisites
Чистим сначала полностью наше окружение
kubectl delete deployments.apps postgres-deployment short-api-deployment short-app-deployment
kubectl delete service mysql-1757409042 postgres-clusterip short-api-clusterip short-app-clusterip
kubectl delete persistentvolumeclaims mysql-1757409042 postgres-pvc
kubectl delete secrets mysql-1757409042 pg-secret postgres-secret short-api-secret
kubectl delete configmaps demo-config mysql-1757409042-test
kubectl delete ingress myingressСтарт
Для начала можно просто: очистить values.yml, очистить templates и перенести в неё наши конфиги

Далее мы можем создать наш первый релиз по этим конфигам.
Тут мы:
- первым аргументом передаём имя релиза
- вторым наименование папки, в корне которой располагается
Chart.yml
$ helm install short-service-release short-service
NAME: short-service-release
LAST DEPLOYED: Tue Sep 9 13:11:32 2025
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: NoneТеперь у нас выложены все сервисы

Helm автоматически создал секрет, который будет относиться к релизу данного чарта и хранить информацию, которая нужна хельму
$ kubectl get secrets
NAME TYPE DATA AGE
sh.helm.release.v1.short-service-release.v1 helm.sh/release.v1 1 4mИнформация представляет собой дату редактирования, имя, владельца, статус и версию
$ kubectl describe secrets sh.helm.release.v1.short-service-release.v1
Name: sh.helm.release.v1.short-service-release.v1
Namespace: default
Labels: modifiedAt=1757412692
name=short-service-release
owner=helm
status=deployed
version=1
Annotations: <none>
Type: helm.sh/release.v1
Data
====
release: 2560 bytesВстроенные объекты
Встроенные объекты Helm
-
Release
-
информация
-
Values - переменные из файла
values.yml -
Chart - данные из файла
Chart.yml -
Files - доступ к любым файлам, кроме стандартных (позволяет получить доступ к любым файлам из файловой системы)
-
Capabilities - информация о кластере (версия кубера, операции и так далее)
-
Templates - информация о текущем шаблоне
Более подробную информацию по каждой из групп объектов можно получить в документации
Применение
Чтобы использовать значения переменных, нужно использовать go-шаблонные строки {{ .Values.<данные_объекта> }}

Обновим конфиг
short-service / templates / demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
key: {{ .Release.Name }}И обновим версию чарта
short-service / Chart.yaml
version: 0.1.1Работа
Чтобы просмотреть наши запущенные шаблоны:
helm ls
Чтобы обновить чарт, нужно будет прогнать upgrade с названием чарта и повторным указанием папки
$ helm upgrade short-service-release short-serv
Release "short-service-release" has been upgraded. Happy Helming!
NAME: short-service-release
LAST DEPLOYED: Tue Sep 9 13:34:12 2025
NAMESPACE: default
STATUS: deployed
REVISION: 2
TEST SUITE: NoneТеперь выведем конфиг, который мы задеплоили и тут можно будет увидеть, что в ключе key находится значение из .Release.Name, которое равняется short-service-release
$ kubectl describe configmaps demo-config
Name: demo-config
Namespace: default
Labels: app.kubernetes.io/managed-by=Helm
Annotations: meta.helm.sh/release-name: short-service-release
meta.helm.sh/release-namespace: default
Data
====
key:
----
short-service-release
BinaryData
====
Events: <none>Задание переменных
Сразу подставим в объект Values значение, которое будет доступно в Helm шаблонах
short-service / values.yaml
name: ValeryИ опишем нашу конфигурацию, которая будет тянуть переменные из Helm объектов
short-service / templates / demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
key: {{ .Release.Name }}
name: {{ .Values.name }}
chart: {{ .Chart.AppVersion }}И теперь, чтобы проверить результат, нам можно просто прогнать команду генерации нашего результата, но с флагами:
--debug, что выведет результат в консоль--dry-run, что не будет генерировать результат
$ helm install --debug --dry-run short-service-release short-serv
CHART PATH: /Users/zeizel/projects/12-kubernetes-1/short-serv
NAME: short-service-release
LAST DEPLOYED: Tue Sep 9 13:50:25 2025
NAMESPACE: default
STATUS: pending-install
REVISION: 1
TEST SUITE: None
USER-SUPPLIED VALUES:
{}
COMPUTED VALUES:
name: Valery
HOOKS:
MANIFEST:
---
# Source: short-serv/templates/demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
key: short-service-release
name: Valery # <- подставилось имя из переменной
chart: 1.16.0 # <- доставли версию приложенияЕсли нам нужно заменить Computed Values и в рамках другого окружения заменить параметры, мы можем передать флаг --set, который позволит в моменте кастомизировать значение
$ helm install --debug --dry-run short-service-release --set name=Oleg short-serv
CHART PATH: /Users/zeizel/projects/12-kubernetes-1/short-serv
NAME: short-service-release
LAST DEPLOYED: Tue Sep 9 13:54:02 2025
NAMESPACE: default
STATUS: pending-install
REVISION: 1
TEST SUITE: None
USER-SUPPLIED VALUES:
name: Oleg
COMPUTED VALUES:
name: Oleg
HOOKS:
MANIFEST:Функции и pipelines
В Helm присутствует удобная работа с функциями, которая берёт следующие данные в строке и преобразует их
Все операции находятся так же в документации
Функции
Например функция upper переведёт в UpperCase значение, а quote переведёт число в явную строку
short-service / templates / demo-config.yml
data:
key: {{ .Release.Name }}
name: {{ upper .Values.name }}
chart: {{ quote .Chart.AppVersion }}Результат дебага:
data:
key: short-service-release
name: VALERY
chart: "1.16.0"Пайплайны
Пайплайны работают таким образом:
- Сначала мы получили значение
- Далее используем
|, который инициализирует передачу значения в функцию дальше - В следующей функции мы получаем результат и так же передаём его дальше
Например:
now- получит текущую датуdate "2006-01-02"- передаст дату дальшеquote- обернёт значение в кавычки
short-service / templates / demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
key: {{ .Release.Name }}
name: {{ .Values.name | upper | quote }}
chart: {{ .Chart.AppVersion | quote }}
date: {{ now | date "2006-01-02" | quote }}data:
key: short-service-release
name: "VALERY"
chart: "1.16.0"
date: "2025-09-09"Упражнение - Шаблон для app
Дефайним общие переменные, которые будем использовать в приложении app
short-service / values.yaml
# отделили переменные по домену
app:
name: short-app
image: antonlarichev/short-app
version: v1.4 # версия image
components: frontend
port: 80
replicas: 1
limits:
memory: "128Mi"
cpu: "100m"Передадим в конфигурацию тег изображения, который будем использовать для получения изображения с нашим фронтом.
Так как у нас в переменных используется вложенный объект, то обращаемся по .Values(объект).app(домен).version(значение)
short-service / templates / demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
name: {{ .Values.app.version | upper | quote }}Передаём в сервис приложения наименование, порт и компоненты
short-service / templates / app-service.yml
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.app.name }}-clusterip
spec:
type: ClusterIP
ports:
- port: {{ .Values.app.port }}
protocol: TCP
selector:
components: {{ .Values.app.components }}Опишем деплой.
Если нам нужно сконкатенировать строку из нескольких переменных, мы можем обернуть это в кавычки по типу:
"{{ .Values.<переменная> }}:{{ .Values.<переменная> }}"
short-service / templates / app-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.app.name }}-deployment
spec:
replicas: {{ .Values.app.replicas }}
selector:
matchLabels:
components: {{ .Values.app.components }}
template:
metadata:
labels:
components: {{ .Values.app.components }}
spec:
containers:
- name: {{ .Values.app.name }}
image: "{{ .Values.app.image }}:{{ .Values.app.version }}"
ports:
- containerPort: {{ .Values.app.port }}
resources:
limits:
memory: {{ .Values.app.limits.memory }}
cpu: {{ .Values.app.limits.cpu }}Упражнение - Функции
Изначально, все значения из объектов, которые мы получаем с помощью шаблонов, мы получаем в виде строки
Чтобы передать объект limits из переменных окружения, нам нужно:
- перевести его из строки в yml с помощью
toYaml - и с помощью
nindentмы сделаем правильные отступы для этого YML. В эту функцию нужно передать правильное количество отступов (в нашем случае 14)
short-service / templates / app-deployment.yml
spec:
containers:
- name: {{ .Values.app.name }}
image: "{{ .Values.app.image }}:{{ .Values.app.version }}"
ports:
- containerPort: {{ .Values.app.port }}
resources:
limits: {{ .Values.app.limits | toYaml | nindent 14 }}Теперь в дебаге можно увидеть, что у нас на выходе получилась полностью правильная и завершённая конфигурация k8s для сервиса app
$ helm install --debug --dry-run short-service-release short-serv
install.go:225: 2025-09-09 18:42:29.016768 +0300 MSK m=+0.099265251 [debug] Original chart version: ""
install.go:242: 2025-09-09 18:42:29.017267 +0300 MSK m=+0.099764751 [debug] CHART PATH: /Users/zeizel/projects/12-kubernetes-1/short-serv
NAME: short-service-release
LAST DEPLOYED: Tue Sep 9 18:42:29 2025
NAMESPACE: default
STATUS: pending-install
REVISION: 1
TEST SUITE: None
USER-SUPPLIED VALUES:
{}
COMPUTED VALUES:
app:
components: frontend
image: antonlarichev/short-app
limits:
cpu: 100m
memory: 128Mi
name: short-app
port: 80
replicas: 1
version: v1.4
HOOKS:
MANIFEST:
---
# Source: short-serv/templates/demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
name: "V1.4"
---
# Source: short-serv/templates/app-service.yml
apiVersion: v1
kind: Service
metadata:
name: short-app-clusterip
spec:
type: ClusterIP
ports:
- port: 80
protocol: TCP
selector:
components: frontend
---
# Source: short-serv/templates/app-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: short-app-deployment
spec:
replicas: 1
selector:
matchLabels:
components: 1
template:
metadata:
labels:
components: 1
spec:
containers:
- name: short-app
image: "antonlarichev/short-app:v1.4"
ports:
- containerPort: 80
resources:
limits:
cpu: 100m
memory: 128MiПродвинутые шаблоны
if-else
В шаблонизаторе Helm доступно управление потоками
Представим такую ситуацию, что в проде нам нужно передавать переменную, а на тесте эта переменная будет необязательной
Зададим переменную, в которой будем хранить текущее окружение
short-service / values.yaml
env: test # productionС помощью конструкций:
ifначинаем операцию сравненияelseставим conditionalendзаканчиваем операцию
Оператор eq проверяет равенство следующих переданных в него значений
short-service / templates / demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
name: {{ .Values.app.version | upper | quote }}
{{- if eq .Values.env "production"}}
paymentToken: "1234"
{{- else }}
paymentToken: false
{{- end }}Примечание
Когда мы переносим на новую строку операторы внутри {{}}, они тоже попадают в итоговую сборку и представляют собой пустую строку. Чтобы Helm собирал конфиги без лишних отступов, нам нужно будет добавлять - в начале шаблонов, чтобы эти темплейты после процессинга вырезались
То есть такая запись тоже будет валидна
data:
name: {{ .Values.app.version | upper | quote }}
{{ if eq .Values.env "production"}}
paymentToken: "1234"
{{ else }}
paymentToken: false
{{ end }}Но будет собирать файл с такими пробелами

with
Оператор with позволяет нам создать скоуп доступа к Values, относительно которого у нас будет идти обращение к его переменным. Это сильно упрощает работу с вложенными объектами.
Добавим значения, которые имеют достаточно длинный путь для их получения, но он будет соответствовать классической структуре сервиса k8s:
short-service / values.yaml
value:
requirements:
limits:
memory: "128Mi"
cpu: "100m"
Тут, внутри блока with, мы получили прямой доступ ко всем ключам объекта .Values.value.requirements.limits и теперь можем обращаться к ним напрямую через .memory и .cpu.
Однако тут у нас появляется проблема по работе с глобальной областью видимости и доступ к ней предоставляется теперь внутри блока через $, а не просто через .
short-service / templates / demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
name: {{ .Values.app.version | upper | quote }}
{{- if eq .Values.env "production"}}
paymentToken: "1234"
{{- else }}
paymentToken: false
{{- end }}
{{- with .Values.value.requirements.limits }}
memory: {{ .memory }}
cpu: {{ .cpu }}
version: {{ $.Release.Name }}
{{- end }}А вот так бы выглядела запись без with:
data:
memory: {{ .Values.value.requirements.limits.memory }}
cpu: {{ .Values.value.requirements.limits.cpu }}На выходе из дебага мы получаем такую строку:
data:
name: "V1.4"
paymentToken: 1234
memory: 128Mi
cpu: 100m
version: short-service-releaserange
Оператор range позволит нам оперировать над массивами элементов и применять их в шаблонах
Добавим в Values список пользователей
short-service / values.yaml
users:
- Valery
- VasiaСамый простой вариант работы с range - это описание перебора. Внутри блока range в качестве нашего скоупа . будет являться текущий элемент массива
|- - символ мультистрочности
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
name: {{ .Values.app.version | upper | quote }}
# вывод обычного списка
users: |-
{{- range .Values.users }}
- {{ . }}
{{- end }}
Поменяем список пользователей
short-service / values.yaml
users:
- name: Valery
role: admin
- name: Vasia
role: manager
# Valery: adminИ в данных нашего сервиса будем шарить список типа Имя: роль. Берём .Values.users и описываем шаблон элементов списка
Тут нам не нужен будет символ мультистрочности, так как это кусочек YAML
short-service / templates / demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
name: {{ .Values.app.version | upper | quote }}
# работа со списком
users:
{{- range .Values.users }} # range
{{ .name }}: {{ .role }} # преобразование списка
{{- end }}
Переменные
В рамках наших шаблонов нам доступно использование переменных
Переменные:
- начинаются с
$ - как в go присваивают значение через
:= - доступны в рамках всего файла
short-service / templates / demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
name: {{ .Values.app.version | upper | quote }}
# объявление переменной
{{- $map := .Release.Name | upper | quote }}
map: {{ $map }}
# использование переменной в массиве
users:
{{- range $index, $user := .Values.users }}
{{ $user.name }}: "{{ $user.role }} - {{ $index }}"
{{- end }}
tuple
Иногда нам нужна возможность создать быстро список внутри шаблона. Чтобы не заносить никуда готовый список элементов, мы можем прямо на месте воспользоваться функцией tuple, которая создаст и вернёт кортеж
short-service / templates / demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
data:
name: {{ .Values.app.version | upper | quote }}
# список
users: |-
# создаём список ["Anton", "Vasia"]
{{- range tuple "Anton" "Vasia" }}
- {{ . }}
{{- end }}В итоге получаем список users прямо на месте

template
Часто у нас появляется в разработке такие куски кода, которые повторяются регулярно в приложении. Для упрощения работы с такими повторяющимися кусками кода, Helm предоставляет возможность работы с template конструкциями
- объявление шаблона происходит через
defineс определением его имени - применение шаблона происходит через
template, где мы первым аргументом передаёмимя_шаблонаа вторым контекст., из которого сам шаблон будет брать данные
short-service / templates / demo-config.yml
{{- define "chart.labels" }}
labels:
date: {{ now | htmlDate }}
version: {{ .Values.app.version }}
{{- end}}
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
{{- template "chart.labels" . }}
data:
name: {{ .Values.app.version | upper | quote }}include
Уже функция include позволяет в Helm импортировать отдельный кусок шаблона из одного файла в другой
Создание шаблона
Вынесем шаблон наших метаданных в отдельный yml.
По умолчанию, все файлы, которые находятся в template, считаются файлами конфигурации k8s. Чтобы отцепить файл от конфигураций, нам нужно в начале его именования выделить его _.
В одном файле может использоваться сразу несколько шаблонов.
short-service / templates / _temp.yml
{{- define "chart.labels" }}
date: {{ now | htmlDate }}
version: {{ .Values.app.version }}
{{- end }}Применение шаблона
И через indlude применим по названию шаблон из другого файла. Тут так же нужно передать контекст. В нашем случае, так же нужно будет через indent указать количество отступов
short-service / templates / demo-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-config
labels:
{{- include "chart.labels" . | indent 4 }}
data:
name: {{ .Values.app.version | upper | quote }}Template vs Include
Template более удобный, когда нам нужно вынести уникальную логику для определённого шаблона
Include позволяет более гибко регулировать отступы через indent
Упражнение - API + Оптимизация chart
Теперь опишем шаблонами сервисы для API
Тут нам нужно добавить группы api для описания api-проекта, database для описания проекта бд и postgres для сохранения данных специфичных для postgre
Пока секреты данных для подключения к БД оставим в открытом виде тут
short-service / values.yaml
app:
name: short-app
image: antonlarichev/short-app
version: v1.4
components: frontend
port: 80
replicas: 1
limits:
memory: "128Mi"
cpu: "100m"
api:
name: short-api
image: antonlarichev/short-api
version: v1.0
components: backend
port: 3000
replicas: 1
limits:
memory: "500Mi"
cpu: "200m"
# env переменные из сервиса Secret
envs:
- DATABASE_URL
postgres:
name: postgres
image: antonlarichev/short-api
version: v1.0
components: backend
port: 5432
limits:
memory: "500Mi"
cpu: "200m"
database:
user: demo
password: demo
db: demoШаблон, который будет представлять собой элемент переменной окружения
short-service/templates/_common.tpl
{{- define "env.template" }}
- name: {{ .env }}
valueFrom:
secretKeyRef:
name: "{{ .name }}-secret"
key: {{ .env }}
{{- end }}Далее перенесём весь конфиг api сюда с переносом данных из Values.
livenessProbe шаблонировать не нужно - это достаточно уникальная часть.
short-service / templates / api-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.api.name }}-deployment
spec:
replicas: {{ .Values.api.replicas }}
selector:
matchLabels:
components: {{ .Values.api.components }}
template:
metadata:
labels:
components: {{ .Values.api.components }}
spec:
containers:
- name: {{ .Values.api.name }}
image: "{{ .Values.api.image }}:{{ .Values.api.version }}"
ports:
- containerPort: {{ .Values.api.port }}
resources:
limits: {{ .Values.api.limits | toYaml | nindent 14 }}
# переменные окружения
env: # тут мы используем шаблон для задания переменных окружения
{{- range .Values.api.envs }}
{{- $data /:= dict "name" $.Values.api.name "env" . }}
{{- include "env.template" $data | indent 12 }}
{{- end }}
livenessProbe:
exec:
command:
- curl
- --fail
- http://localhost:3000/api
initialDelaySeconds: 30
periodSeconds: 5
failureThreshold: 1Описание Secret.
Тут нам нужно будет переработать секрет и воспользоваться функцией printf. В неё первым параметром передадим шаблонную строку с %s (слотами) а далее переменными, которые по порядку встанут в эти слоты.
Далее применим энкод в base64 через b64enc и обернём в кавычки quote
Если нам нужно выполнить вложенные преобразования, то мы можем обернуть значение в () и внутри описать операции пайплайном над данными
short-service / templates / api-secret.yml
apiVersion: v1
kind: Secret
metadata:
name: {{ .Values.api.name }}-secret
type: Opaque
data:
DATABASE_URL: {{ printf "postgresql://%s:%s@%s-clusterip:%d/%s"
# параметры подключения
.Values.database.user
.Values.database.password
.Values.database.db
# сервис postgres
.Values.postgres.name
(.Values.postgres.port | int64 ) | b64enc | quote }}Описание ClusterIP
short-service / templates / api-service.yml
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.api.name }}-clusterip
spec:
type: ClusterIP
ports:
- port: {{ .Values.api.port }}
protocol: TCP
selector:
components: {{ .Values.api.components }}Упражнение - PostgreSQL
Определим переменные окружения для postgres сервиса. Тут нам базово нужны переменные, которые будут отвечать за: подключение к определённой базе, пользователем с паролем
short-service / values.yaml
postgres:
name: postgres
image: postgres
version: 16.0
components: postgres
port: 5432
limits:
memory: "500Mi"
cpu: "300m"
envs:
- POSTGRES_DB
- POSTGRES_USER
- POSTGRES_PASSWORDОпишем сервис для выделения пространства под наш сервис
short-service / templates / postgres-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: "{{ .Values.postgres.name }}-pvc"
spec:
resources:
requests:
storage: 1Gi
accessModes:
- ReadWriteOnceСервис секретов будет в себе хранить данные для подключения к базе
short-service / templates / postgres-secret.yml
apiVersion: v1
kind: Secret
metadata:
name: {{ .Values.postgres.name }}-secret
type: Opaque
data:
POSTGRES_DB: {{ .Values.database.db | b64enc }}
POSTGRES_USER: {{ .Values.database.user | b64enc }}
POSTGRES_PASSWORD: {{ .Values.database.password | b64enc }}Сервис постгреса для упрощенного доступа
short-service / templates / postgres-service.yml
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.postgres.name }}-clusterip
spec:
type: ClusterIP
ports:
- port: {{ .Values.postgres.port }}
protocol: TCP
selector:
components: {{ .Values.postgres.components }}Деплоймент постгреса
short-service / templates / postgres-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.postgres.name }}-deployment
spec:
replicas: 1
selector:
matchLabels:
components: {{ .Values.postgres.components }}
template:
metadata:
labels:
components: {{ .Values.postgres.components }}
spec:
containers:
- name: {{ .Values.postgres.name }}
image: "{{ .Values.postgres.image }}:{{ .Values.postgres.version }}"
ports:
- containerPort: {{ .Values.postgres.port }}
resources:
limits: {{ .Values.postgres.limits | toYaml | nindent 14 }}
env:
{{- range .Values.postgres.envs }}
{{- $data := dict "name" $.Values.postgres.name "env" . }}
{{- include "env.template" $data | indent 12 }}
{{- end }}
volumeMounts:
- name: "{{ .Values.postgres.name }}-data"
mountPath: /var/lib/postgresql/data
subPath: postgres
volumes:
- name: "{{ .Values.postgres.name }}-data"
persistentVolumeClaim:
claimName: "{{ .Values.postgres.name }}-pvc"Управление репозиторием
Notes txt
NOTES.txt файл хранит в себе информацию, которая выйдет после установки (helm install) нашего чарта
short-service / templates / NOTES.txt
Вы успешно установили приложение {{ .Release.Name }} {{ .Chart.Version }}
Развёртка приложения
Дошаблонируем ingress сервис
short-service / templates / ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myingress
annotations:
nginx.ingress.kubernetes.io/add-base-url: "true"
spec:
ingressClassName: nginx
rules:
- host: demo.test
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: {{ .Values.app.name }}-clusterip
port:
number: {{ .Values.app.port }}
- pathType: Prefix
path: "/api"
backend:
service:
name: {{ .Values.api.name }}-clusterip
port:
number: {{ .Values.api.port }}Далее останется:
- обновить шаблоны
- отследить запуск всех сервисов
- проверить миграции в базе и если данных нет, то создать таблицы (
CREATE TABLE)
helm upgrade short-service-release short-service
kubectl get allСоздание репозитория
Для создания отдельного репозитория с нашим собранным k8s из helm, нам нужно будет:
- Создать отдельный репозиторий
mkdir helm-pkg
git init
touch README.md- Генерация итогового бандла
Helm позволяет сгенерировать итоговый бандл репозитория чартов. Путь генерации будет на месте вызова. Путь в команде указывается на директорию helm-проекта
helm package ../<helm-orig>/short-service
- Создаём точку репозитория helm
Теперь нам нужно сгенерировать индекс с метаданными для использования helm-репозитория
helm repo index .- Отправляем helm-репозиторий в github
Использование репозитория
- Собираем raw-путь
Перейдём в репозиторий и получим Raw-путь из которого нужно будет только удалить /файл

Получим такую строку с репозиторием, которая кончается веткой
https://raw.githubusercontent.com/ZeiZel/helm-repo/refs/heads/main
- Генерируем токен для авторизации в репозиторий
Генерируем токен для внешнего подключения к приватному репозиторию
https://github.com/settings/personal-access-tokens/new

И на выходе получаем такой токен:
github_pat_11AQVJOFY0uCxGD5LhEJkn_<...>
- Подключаем репозиторий
Подключаем новый репозиторий с нашим сервисом. Сюда мы должны передать наш ник и сгенерированный токен
$ helm repo add my --username ZeiZel --password github_pat_<...> https://raw.githubusercontent.com/ZeiZel/helm-repo/refs/heads/main
"my" has been added to your repositoriesТеперь у нас появился репозиторий my, в котором располагается short-service
$ helm repo list
NAME URL
stable https://charts.helm.sh/stable
my https://raw.githubusercontent.com/ZeiZel/helm-repo/refs/heads/main
$ helm search repo short
NAME CHART VERSION APP VERSION DESCRIPTION
my/short-service 0.1.1 1.16.0 URL Shortner serviceВ качестве альтернативы стандартным удалённым репозиториям, можно поднять специально museum, который будет хранить helm-репозитории
Использование Charts
Uninstall
Часто может быть такая ситуация, что мы локально протестировали работу сервисов и теперь нам нужно очистить все сервисы, которые связаны с данным шаблоном helm
Команда uninstall удалит все сервисы (поды, деплои, pvc, секреты, конфиги и так далее), которые связаны с данным релизом
helm uninstall short-service-releaseИ далее раскатим релиз из нашего репозитория (прошлый урок)
helm install short-app-release my/short-serviceRollback
list выводит список наших helm-проектов
history позволит подробно вывести информацию по отдельному helm-проекту
helm list
helm history short-app-release
Поменяем что-нибудь в проекте и обновим релиз
helm upgrade short-app-release ./short-serviceПоявился новый релиз в history

Чтобы откатиться, нужно воспользоваться командой rollback и откатить релиз
$ helm rollback short-app-release 1
Rollback was a success! Happy Helming!И теперь history переведёт все прошлые релизы в supressed и восстановит первый релиз

Откат происходит полноценно. Если k8s дефолтно умеет откатывать только deployments, то helm может откатить все сервисы, которые мы изменили.
Отладка релиза
Lint
lint позволяет проверить проект на поддержание best practices
$ helm lint short-service
==> Linting short-service
[INFO] Chart.yaml: icon is recommended
1 chart(s) linted, 0 chart(s) failedTemplate
template test позволяет вывести собранный конфиг из всех описанных шаблонов (выведет то же самое, что и --debug --dry-run)
$ helm template test ./short-service
---
# Source: short-service/templates/api-secret.yml
apiVersion: v1
kind: Secret
metadata:
name: short-api-secret
type: Opaque
data:
DATABASE_URL: "cG9zdGdyZXNxbDovL2RlbW86ZGVtb0Bwb3N0Z3Jlcy1jbHVzdGVyaXA6NTQzMi9kZW1v"
---
# Source: short-service/templates/postgres-secret.yml
apiVersion: v1
kind: Secret
metadata:
name: postgres-secret
type: Opaque
data:
POSTGRES_DB: ZGVtbw==
POSTGRES_USER: ZGVtbw==
POSTGRES_PASSWORD: ZGVtbw==
---
# Source: short-service/templates/postgres-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
...Get
get позволяет нам получить отдельные данные по нашему релизу
- получаем
values- получаем пользовательскиеvalues, которые были переданы в команде при запускеhooksmanifestmetadatanotes
Получение кастомных значений
$ helm get values short-app-release
USER-SUPPLIED VALUES:
nullПолучение полной информации по релизу
$ helm get all short-app-release
NAME: short-app-release
LAST DEPLOYED: Sat Sep 13 22:44:18 2025
NAMESPACE: default
STATUS: deployed
REVISION: 3
CHART: short-service
VERSION: 0.1.1
APP_VERSION: 1.16.0
USER-SUPPLIED VALUES:
null
COMPUTED VALUES:
api:
components: backend
envs:Тесты
Helm позволяет нам описывать тесты, которые будут представлять собой поды, выполняющие фиксированные операции
Тест является хуком в рамках Helm
Hook - это сущность, которая должна отработать в зависимости от определённых условий
Тут мы опишем сервис, который будет проверять загруженность пода командой wget
short-service / templates / tests / api-test.yml
apiVersion: v1
kind: Pod
metadata:
name: "{{ .Release.Name }}-api-test"
labels:
# триггерится на компонентах из api
components: {{ .Values.api.components }}
annotations:
# это хук, который отработает во время тестов
"helm.sh/hook": test
spec:
containers:
- name: wget
image: busybox
command: ['wget']
# отправляем запрос на ClusterIP сервса API по порту из values
args: ['{{ .Values.api.name }}-clusterip:{{ .Values.api.port }}/api']
# нам не нужно перзапускать его после отработки
restartPolicy: NeverОбновляем под и командой test запускаем тесты
$ helm upgrade short-app-release ./short-service
$ helm test short-app-release
NAME: short-app-release
LAST DEPLOYED: Sat Sep 13 23:06:52 2025
NAMESPACE: default
STATUS: deployed
REVISION: 4
TEST SUITE: short-app-release-api-test
Last Started: Sat Sep 13 23:07:49 2025
Last Completed: Sat Sep 13 23:08:23 2025
Phase: Failed
NOTES:
Вы успешно установили приложение short-app-release 0.1.1
Error: 1 error occurred:
* pod short-app-release-api-test failedШифрование секретов
Сейчас до сих пор сохраняется проблема, что мы храним секреты публично без возможности скрыть их из репозитория
values.yml
database:
user: demo
password: demo
db: demoHelm secrets
Есть множество решений, но самый простой и быстрый - это использование плагина для helm.
Решает вышеописанную проблему плагин helm-secrets.
helm plugin install https://github.com/jkroepke/helm-secretsПосле установки, у нас появляется команда secrets, которая предоставляет несколько полезных для нас операций
edit
helm secretsGpg
Но для кодирования секретов используются gpg ключи. Для работы с ключами понадобится пакет
brew install gpgОсновные команды gpg:
# выведет список ключей
gpg --list-keys
# сгенерирует ключ
gpg --gen-keyВо время генерации, нужно будет дважды ввести пароль-фразу

После генерации ключа, нам нужно будет воспользоваться сгенерированным публичным ключом

Sops
Sops позволяет на основе сгенерированного gpg-ключа собрать secrets.yml
brew install sopsГенерируем YML с секретами на основе нашего публичного gpg-ключа.
sops -p 897FA5D8EBA85AA44F6C9B5DDB668858DCE2B6DE secrets.ymlПосле вызова этой команды, у нас откроется vi-редактор, в который мы должны будем вставить все секреты в открытом виде, чтобы в итоге получить готовый файл с секретами такого типа:
secrets.yml
database:
user: ENC[AES256_GCM,data:NOXT7g==,iv:6PHFtr77zY4njs5E5T9n+o4wlfuEci2qahDVuzyU+KM=,tag:Uhav/nkLYIEX3JB51lidKA==,type:str]
password: ENC[AES256_GCM,data:CJBA2w==,iv:eUiB5vC+CMQPLpZI3EHBttvTvWaA1c6wpcg0TXE1Z5s=,tag:Tso8m6qXvpN312os7syiLQ==,type:str]
db: ENC[AES256_GCM,data:gW+Byw==,iv:FjPBavBwLSxiVpLdilV4zl2/UtNe7FNPYZihrQ7tFik=,tag:1OOFZm6EAn0jVKB1DDtxOw==,type:str]
sops:
lastmodified: "2025-09-13T20:30:37Z"
mac: ENC[AES256_GCM,data:2t9Ol1y39IZf9AvRi/UZ3ZLt93ceaZnLNFMZVTuAm9PJ7kkB9PEW6aIxuVjhugCW4ejk+V6KEpX8geOibe66qDm4QgoUxXGxZIZBg2reGzAdvICuEcIowvM4ctl1DBq8M9GWiviqDmeYQN+YnQYfQemQe+PuAlvGyMLxD1Gwzbk=,iv:OGEs6OKX55+H4wVbHljBYFFM5lpK2cB8wJp3i5K4GtY=,tag:ADDjR+XKDm25SRc0G4SYzg==,type:str]
pgp:
- created_at: "2025-09-13T20:30:15Z"
enc: |-
-----BEGIN PGP MESSAGE-----
hF4Dc/e0lbILNO8SAQdAyqM6+fu2hYNEzRDe3r3kVuL1/TpTnj1eHSvO2JIf1XUw
3WiTqW+Htk6nG2YpZGWXqkVzaVPHaiNDkO2Zap4OOcUcp7BM0cCxHmSRsembdfa5
1GgBCQIQNytWuwtXljQHpO9e/kKNNr78TEDXkOCd4LMJrMQuHbr5nVyYHK9Fqnh9
MEsQSU9y849oQ6U0AmeJLBawkY9ZGrvkY5SY6CJL2pDTWtP9rS3ee6XXzpOJVgCV
kTe6lACbUch/AQ==
=rDQj
-----END PGP MESSAGE-----
fp: 897FA5D8EBA85AA44F6C9B5DDB668858DCE2B6DE
unencrypted_suffix: _unencrypted
version: 3.10.2Использование секретов
Пока мы не настроили редактирование секретов
$ helm secrets edit secrets.yml
secrets.yml
Failed to get the data key required to decrypt the SOPS file.
Group 0: FAILED
897FA5D8EBA85AA44F6C9B5DDB668858DCE2B6DE: FAILED
- | could not decrypt data key with PGP key:Чтобы у нас появился доступ, нам нужно экспортировать GPG_TTY актуально равный выводу tty.
Уже в окне редактирования останется только ввести пароль-фразу и откроется доступ к редактированию секретов
# установка tty
GPG_TTY=$(tty)
export GPG_TTY
# редактирование
helm secrets edit secrets.ymlМы можем расшифровать так же секреты в консоль
$ helm secrets decrypt secrets.yml
database:
user: demo
password: demo
db: demoЛибо вообще весь файл secrets.yml с помощью флага -i (который работает для decrypt и encrypt)
helm secrets decrypt -i secrets.ymlsecrets.yml
database:
user: demo
password: demo
db: demoОднако при попытке обратно зашифровать секреты, мы получим ошибку
$ helm secrets encrypt secrets.yml
Could not generate data key: [failed Чтобы helm научился зашифровывать обратно, нам нужно указать публичный pgp-ключ в файле .sops.yaml
.sops.yaml
---
creation_rules:
- pgp: "897FA5D8EBA85AA44F6C9B5DDB668858DCE2B6DE"После чего encrypt опять заработает и он опять зашифрует файл
$ helm secrets encrypt -i secrets.ymlsecrets.yml
database:
user: ENC[AES256_GCM,data:FHqlsQ==,iv:HEQK5Gc41hxLw4bsh1DO7yxFGYY/e+ctrK0saKs4mSU=,tag:3nWWbjctJobbeR70Obathg==,type:str]
password: ENCЧтобы применить секреты, нужно вызвать обновление нашего релиза через плагин secrets. Он задекриптит наши секреты, применит их и сразу же обновит релиз
$ helm secrets upgrade short-app-release ./short-service -f ./secrets.yml
[helm-secrets] Decrypt: ./secrets.yml
Release "short-app-release" has been upgraded. Happy Helming!
NAME: short-app-release
LAST DEPLOYED: Sat Sep 13 23:54:54 2025
NAMESPACE: default
STATUS: deployed
REVISION: 5
NOTES:
Вы успешно установили приложение short-app-release 0.1.1
[helm-secrets] Removed: ./secrets.yml.decИ всё работает
$ kubectl get secrets short-api-secret --template={{.data.DATABASE_URL}} | base64 -D
postgresql://demo:demo@postgres-clusterip:5432/demo%Теперь из файла
short-service / values.yamlможно будет удалить блокdatabase, так как теперь мы не храним секьюрные данные в нём. У нас открывается спокойный доступ к отправке нашего кода в репозиторий без страха того, что секреты куда-нибудь утекут.
Разные окружения
Часто на работе может встать такая задача, что нам нужно развернуть сразу несколько окружений для нашего сервиса:
- prod
- stage
- test
Для решения этой проблемы, можно прибегнуть просто к делению секретов по папкам окружений. В таком случае, нам не будет составлять проблем просто указать путь до нужных секретов по нужному окружению.
Создаём папку secrets и распределяем секреты по разным окружениям. Важно сохранить для каждого окружения свои secrets.yml и .sops.yml

Если мы запускаемся на разных кластерах, то нам через конфигурацию kubectl нужно указать правильное подключение к новому кластеру.
Если мы запускаем разные окружения в рамках одного кластера, то обязательно работаем в рамках разных namespace через -n
Заключение
- Конфигурация кластера k8s вручную
- Работа с kubeconfig